ترجمههای کامران بزرگزاد

مباحثی درباره تولید، تغییر، و بازیابی دادهها در پایگاههای داده رابطهای
آلن بیولیو
چرا از این کتاب برای انجام این کارها استفاده کنیم؟
استفاده از حروف مختلف در این کتاب
سیستمهای پایگاه داده غیررابطهای
در ادامه چه چیزهایی خواهند آمد؟
ایجاد و پر کردن یک پایگاه داده
استفاده از ابزار خط فرمان mysql
text (در MySQL و SQL Server) یا clob (در پایگاه داده Oracle)
دادههایی که درباره دادهها هستند
طرحواره اطلاعات (information_schema)
مقدمهای بر آپاچی دریل (Apache Drill)
پرسوجوی فایلها با استفاده از Drill
پایگاههای داده (Databases) اساس بیشتر برنامههای کاربردی را تشکیل میدهند، و در این میان پایگاههای داده رابطهای پرکاربردترین آنها هستند. در اواسط دهه 1970، و همزمان با کارهای دانشمند برجسته علوم رایانهای، ادگار کاد (Edgar Codd)، که زبانی را برای بکارگیری پایگاههای رابطهای طراحی کرد، از دل زبان او، SQL سربرآورد، و به گستردهترین زبان پایگاه دادهها تبدیل شد، و با گذشت بیش از 50 سال، هنوز هم پرکاربردترین زبان در این زمینه است.
از زمان تولد SQL تا به امروز این زبان تحولات زیادی را پشت سر گذاشته و با توجه به نیازهای روز، چندین استاندارد مختلف در این زبان پدید آمده، که تا زمان ترجمه این کتاب، آخرین نسخه آن SQL:2026 است. در این کتاب به بیشتر جنبههای زبان SQL پرداخته شده و خواننده میتواند از سطوح مقدماتی تا پیشرفته با این زبان آشنا پیدا کند. کتاب به 18 فصل تقسیم شده، و برای یادگیری بهتر، در پایان هر فصل تمریناتی گنجانده شده که خواننده میتواند دانش خود را بیازماید. در پیوست ب. کتاب پاسخ این تمرینات نیز آمده.
گرچه در دو دهه اخیر پایگاههای داده غیر رابطهای، مانند NoSQL، Hadoop، و Spark نیز ظهور کردهاند، ولی هنوز هم SQL جایگاه خود را حفظ کرده و احتمالاً تا 20 سال آینده نیز این جایگاه را خواهد داشت. بنابراین یادگیری آن نه تنها اتلاف وقت نیست، بلکه لازم است.
در بازار پایگاههای داده تجاری کلاً چهار پایگاه داده عمده وجود دارد که عبارتند از:
· Oracle Database از شرکت اوراکل
· SQL Server از شرکت مایکروسافت
· DB2 Universal Database از شرکت IBM
· MySQL از شرکت اوراکل
هرچند زبان مشترک همه این پایگاههای داده SQL است، ولی در میان آنها اختلافات اندکی نیز در پیاده سازی SQL وجود دارد. پایگاهی که این کتاب بر آن تکیه دارد و مثالها بر اساس آن ساخته شدهاند، پایگاه داده MySQL است. ولی هرجا لازم بوده تفاوتهای میان پیادهسازی و ویژگیهای خاص هر یک از این پایگاهها نیز توضیح داده شدهاند. بنابراین خواننده یک مرجع کامل از زبان SQL برای پایگاههای داده عمده در دست خواهد داشت.
هدف این کتاب آموزش زبان SQL از سطح ابتدایی تا پیشرفته است و کارش را با مفاهیم ساده شروع کرده و به تدریج به مسائل پیشرفتهتر میپردازد. مخاطبین اصلی این کتاب را کسانی تشکیل میدهند که میخواهند زبان SQL را یاد بگیرند، یا کسانی که با مقدمات این زبان آشنایی دارند ولی میخواهند آن را با عمق بیشتری دنبال کنند.
آلن بیولیو (Alan Beaulieu) مشاور پایگاهها داده، نویسنده، و یک مربی است که در طراحی و پیادهسازی برنامههای کاربردی مرتبط با پایگاههای داده بیش از ۲۵ سال تجربه دارد. او مدرک کارشناسی خود را در رشته تحقیق در عملیات از دانشکده مهندسی دانشگاه کرنل گرفت، و در سال 2005 کارشناسی ارشد خود در رشته نرمافزار را از دانشگاه کالیفرنیا دریافت کرد. او به عنوان یکی از معروفترین نویسندگان کتابهای آموزش SQL شناخته میشود، و در این زمینه، کتابهای او جزء کتابهای پرفروش بودهاند.
بهار 1405
کامران بزرگزاد ایمانی
زبانهای برنامهنویسی دائماً میآیند و میروند، و تعداد بسیار اندکی از زبانهای برنامهنویسی قدیمی وجود دارند که هنوز از آنها استفاده میشود، و قدمت آنها به بیش از یک دهه یا بیشتر باز میگردد. برخی از این زبانهای قدیمی عبارتند از: COBOL، که هنوز به طور گسترده در محیطِ کامپیوترهای بزرگ از آنها استفاده میشود؛ JAVA که در اواسط دهه ۱۹۹۰ متولد شد و به یکی از محبوبترین زبانهای برنامهنویسی تبدیل شده است؛ و C که هنوز هم برای توسعه سیستمعاملها، سرورها، و سیستمهای تعبیهشده بسیار محبوب است. در عرصه پایگاههای داده، ما زبان SQL را داریم که ریشههای آن به دهه ۱۹۷۰ برمیگردد.
در ابتدا SQL به عنوان زبانی برای تولید، تغییر، و بازیابی دادهها از پایگاههای داده رابطهای ایجاد شد که بیش از 50 سال قدمت دارند. با این حال، در طول دهه گذشته و پیشتر، پلتفرمهای داده دیگری مانند Hadoop، Spark و NoSQL توجه زیادی را به خود جلب کردهاند و بازار پایگاههای داده رابطهای را کم کردهاند. با این حال، همانطور که در چند فصل آخر این کتاب اشاره خواهد شد، صرف نظر از اینکه دادهها در جداول، اسناد، یا فایلهای ساده ذخیره شدهاند، زبان SQL همواره در حال تکامل بوده تا بتواند بازیابی دادهها از پلتفرمهای مختلف را تسهیل کند.
شما چه از پایگاه داده رابطهای استفاده کنید و چه نکنید، اگر در حوزه علوم داده، هوش تجاری، یا جنبههای دیگری از تحلیل داده کار میکنید، احتمالاً علاوه بر زبانها یا پلتفرمهای دیگر مانند پایتون و R، باید با SQL آشنا باشید. دادهها در همه جا، در مقادیر بسیار زیاد و با سرعت زیاد در حال زیاد شدن هستند و تقاضا برای استخدام افرادی که میتوانند از این دادهها اطلاعات معناداری را استخراج کنند، زیاد است.
کتابهای زیادی وجود دارند که با شما مثل یک نادان، ابله، یا هر آدم سادهلوح دیگری رفتار میکنند، اما این کتابها معمولاً فقط به موارد سطحی میپردازند. در انتهای دیگر طیف، کتابهای راهنمای مرجع وجود دارند که جزئیات تمام دستورات یک زبان را شرح میدهند، که اگر از قبل ایده خوبی از کاری که میخواهید انجام دهید دارید اما فقط به ترکیب نحوی دستورات (syntax) نیاز دارید، چنین کتابهایی میتواند مفید باشند. این کتاب تلاش میکند تا حد وسط را رعایت کند، و با کمی پیشزمینه از زبان SQL شروع میکند، از اصول اولیه عبور کرده، و سپس به برخی از ویژگیهای پیشرفتهتر میپردازد که حقیقتاً به شما امکان میدهد کارهای جدی انجام دهید. علاوه بر این، این کتاب با فصلی به پایان میرسد که نحوه پرسوجوی دادهها در پایگاههای داده غیررابطهای را نشان میدهد، موضوعی که به ندرت در کتابهای مقدماتی به آن پرداخته میشود.
این کتاب در ۱۸ فصل تنظیم شده است:
تاریخچه پایگاههای داده کامپیوتری، از جمله ظهور مدل رابطهای و زبان SQL را بررسی میکند.
فصل 2، ایجاد و پر کردن پایگاه داده
نحوه ایجاد پایگاه داده MySQL، ایجاد جداول مورد استفاده برای مثالهای این کتاب و پر کردن جداول با دادهها را نشان میدهد.
عبارت select را معرفی میکند و رایجترین بندهای آن (select، from، where) را بیشتر توضیح میدهد.
انواع مختلف شرطهایی که میتوانند در بندِ where مربوط به عبارات select، update یا delete استفاده شوند، را نشان میدهد.
نشان میدهد که چگونه پرسوجوها میتوانند از طریق اتصال جداول، از چندین جدول استفاده کنند.
این فصل در مورد مجموعه دادهها و نحوه تعامل آنها در پرسوجوها است.
فصل 7، تولید، تغییر، و تبدیل دادهها
چندین تابع داخلی که برای تغییر یا تبدیل دادهها از آنها استفاده میشوند را نشان میدهد.
نشان میدهد که چگونه میتوان دادهها را تجمیع کرد.
زیرپرسوجوها (که خودم شخصاً به آنها علاقه دارم) را معرفی میکند و نشان میدهد که چگونه و کجا میتوان از آنها استفاده کرد.
فصل 10، مروری دوباره به اتصال جداول
انواع مختلف اتصال جداول را بیشتر بررسی میکند.
بررسی میکند که چگونه میتوان از منطق شرطی (یعنی if-then-else) در عبارات select، insert، update و delete استفاده کرد.
تراکنشها را معرفی میکند و نحوه استفاده از آنها را نشان میدهد.
ایندکسها و قیود را بررسی میکند.
نحوه ساخت رابطهای کاربری برای محافظت از کاربران در برابر پیچیدگی دادهها را نشان میدهد.
کاربرد دیکشنری دادهها را نشان میدهد.
قابلیتهای مورد استفاده برای تولید رتبهبندیها، زیرجمعها، و سایر مقادیری که به طور گسترده در گزارشدهی و تحلیل استفاده میشوند را پوشش میدهد.
فصل ۱۷، کار با پایگاههای داده بزرگ
تکنیکهایی برای آسانتر کردنِ مدیریت و پیمایش پایگاههای داده بسیار بزرگ را نشان میدهد.
به بررسی تحول زبان SQL برای بازیابی دادهها از پلتفرمهای غیررابطهای میپردازد.
در این کتاب از قراردادهای تایپی زیر استفاده شده است:
حروف ایتالیک
اصطلاحات، URLها، آدرسهای ایمیل، نام فایلها و پسوندهای فایل جدید را نشان میدهد.
حروف عرض ثابت
برای نشان دادن لیست برنامهها و همچنین در پاراگرافها برای اشاره به عناصر برنامه مانند نام متغیرها یا توابع، پایگاههای داده، انواع دادهها، متغیرهای محیطی، دستورات و کلمات کلیدی استفاده میشود.
حروف ایتالیک با عرض ثابت
متنی را نشان میدهد که باید با مقادیر ارائه شده توسط کاربر یا با مقادیر تعیین شده توسط متن جایگزین شود.
حروف عرض ثابت، پررنگ
دستورات یا متنهای دیگری را نشان میدهد که باید توسط کاربر به صورت تحتاللفظی تایپ شوند.
|
توجه یک نکته، پیشنهاد، یا یادداشت عمومی را نشان میدهد. برای مثال، من از یادداشتها برای اشاره به ویژگیهای جدید و مفید در Oracle9i استفاده میکنم. |
|
هشدار هشدار یا احتیاط را نشان میدهد. برای مثال، اگر یک عبارت SQL خاص با دقت استفاده نشود، به شما خواهم گفت که آیا ممکن است عواقب ناخواستهای داشته باشد یا خیر . |
برای آزمایش دادههای استفاده شده برای مثالهای این کتاب، دو گزینه دارید:
نسخه سرور MySQL 8.0 (یا بالاتر) را دانلود و نصب کنید و پایگاه داده نمونه Sakila را از
https://dev.mysql.com/doc/index-other.html بارگذاری کنید.
برای دسترسی به MySQL Sandbox به آدرس
https://www.katacoda.com/mysql-db-sandbox/scenarios/mysql-sandbox
بروید، که پایگاه داده نمونه Sakila را در یک نمونه MySQL بارگذاری کرده است. شما باید یک حساب کاربری (رایگان) Katacoda ایجاد کنید. سپس، روی دکمه Start Scenario کلیک کنید.
اگر گزینه دوم را انتخاب کنید، به محض شروع سناریو، یک سرور MySQL نصب و راهاندازی میشود و سپس طرح و دادههای Sakila بارگذاری میشوند. وقتی آماده شد، یک اعلان استاندارد mysql> ظاهر میشود که بعد از آن میتوانید شروع به پرسوجو از پایگاه داده نمونه کنید. این قطعاً سادهترین گزینه است و پیشبینی میکنم که اکثر خوانندگان این گزینه را انتخاب کنند. اگر این گزینه برای شما مناسب به نظر میرسد، میتوانید به بخش بعدی بروید.
اگر ترجیح میدهید کپی خودتان از دادهها را داشته باشید و میخواهید تغییراتی که ایجاد کردهاید دائمی باشند، یا اگر فقط علاقهمند به نصب سرور MySQL روی دستگاه خودتان هستید، ممکن است گزینه اول را ترجیح دهید. همچنین میتوانید از یک سرور MySQL که در محیطی مانند Amazon Web Services یا Google Cloud میزبانی میشود، استفاده کنید. در هر صورت، باید خودتان کار نصب و پیکربندی را انجام دهید، زیرا فراتر از محدوده این کتاب است. پس از در دسترس بودن پایگاه داده، باید چند مرحله را برای بارگیری پایگاه داده نمونه Sakila دنبال کنید.
ابتدا باید کلاینت خط فرمان mysql را اجرا کنید و یک رمز عبور وارد کنید، و سپس مراحل زیر را انجام دهید:
به آدرس
https://dev.mysql.com/doc/index-other.html
بروید و فایلهای مربوط به «پایگاه داده sakila » را از بخش « Example Databases » دانلود کنید.
فایلها را در یک دایرکتوری محلی مانند C:\temp\sakila-db قرار دهید (این برای دو مرحله بعدی استفاده میشود، اما باید آن را با مسیر دایرکتوری خودتان جایگزین کنید).
عبارت source c:\temp\sakila-db\sakila-schema.sql را تایپ کرده و دکمه Enter را بزنید.
source c:\temp\sakila-db\sakila-data.sql
را تایپ کنید. و Enter را فشار دهید.
اکنون باید یک پایگاه دادهی فعال داشته باشید که با تمام دادههای مورد نیاز برای مثالهای این کتاب پر شده باشد.
قبل از اینکه آستینهایمان را بالا بزنیم و کارمان را شروع کنیم، برای اینکه بتوانیم چگونگی تکامل پایگاههای داده رابطهای و زبان SQL را بهتر درک کنیم، مفید خواهد بود تا مرور کوتاهی بر تاریخچه فناوری پایگاه داده داشته باشیم. بنابراین، میخواهم با معرفی برخی مفاهیم اولیه پایگاه داده و نگاهی به تاریخچه ذخیرهسازی و بازیابی دادههای کامپیوتری شروع کنم.
|
توجه برای آن دسته از خوانندگانی که مشتاق هستند زودتر به مبحث پرسوجوها وارد شوند، میتوانند به فصل ۳ مراجعه کنند، اما توصیه میکنم بعداً به دو فصل اول بازگردند تا تاریخچه و کاربرد زبان SQL را بهتر درک کنند. |
یک پایگاه داده چیزی بیش از مجموعهای از اطلاعات نیست که با هم مرتبط هستند. به عنوان مثال، یک دفترچه تلفن، نوعی از پایگاه داده است که دربردارنده نامها، شماره تلفنها، و آدرسهای همه افرادی است که در یک منطقه خاص زندگی میکنند. در حالی که یک دفترچه تلفن مطمئناً یک پایگاه داده فراگیر و پرکاربرد است، فاقد موارد زیر است:
· پیدا کردن شماره تلفن یک شخص میتواند زمانبر باشد، به خصوص اگر دفترچه تلفن شامل تعداد زیادی شماره باشد.
· یک دفترچه تلفن فقط از طریق نام خانوادگی فهرستبندی میشود، بنابراین یافتن نام افرادی که در یک آدرس خاص زندگی میکنند، اگرچه از نظر تئوری امکانپذیر است، اما کاربرد عملی برای این پایگاه داده ندارد.
· از لحظه چاپ دفترچه تلفن، با ورود یا خروج افراد به یک منطقه، تغییر شماره تلفن یا نقل مکان به مکان دیگری در همان منطقه، دقت اطلاعات کمتر و کمتر میشوند.
همان کمبودهایی که در یک دفترچه تلفن وجود دارد، میتواند در مورد هر سیستم ذخیرهسازی دستی دادهها، مانند سوابق بیماران، که در کُمدهای بایگانی ذخیره میشود، نیز صدق کند. به دلیل ماهیت دست و پا گیر پایگاههای داده کاغذی، برخی از اولین برنامههای کامپیوتری شامل سیستمهای پایگاه داده بودند که مکانیسمهای ذخیرهسازی و بازیابی دادههای کامپیوتری هستند. از آنجا که یک سیستم پایگاه داده، اطلاعات را به صورت الکترونیکی و نه روی کاغذ ذخیره میکند، یک سیستم پایگاه داده قادر است دادهها را سریعتر بازیابی کند، دادهها را به روشهای مختلف فهرستبندی کند، و اطلاعات بهروز شده را به کاربران خود ارائه دهد.
در سیستمهای پایگاه داده اولیه، دادههای ذخیره شده روی نوارهای مغناطیسی مدیریت میشد. از آنجا که عموماً تعداد نوارهای مغناطیسی بسیار بیشتر از تعداد دستگاههای نوارخوان بود، تکنسینها وظیفه داشتند نوارها را در صورت درخواست دادههای خاص، بارگذاری و تخلیه کنند. از آنجا که کامپیوترهای آن دوران حافظه بسیار کمی داشتند، درخواستهای متعدد برای دادههای مشابه، معمولاً مستلزم خواندن چندین بار دادهها از نوار بود. در حالی که این سیستمهای پایگاه داده پیشرفت قابل توجهی نسبت به پایگاههای داده بود که روی مقوا پانچ میشدند، اما با آنچه با فناوری امروزی امکانپذیر شده، بسیار فاصله دارند. (سیستمهای پایگاه داده مدرن میتوانند دادههایی در اندازه پتابایت (petabytes) را مدیریت کنند که توسط خوشههایی از سرورها، که هر کدام دهها گیگابایت از دادهها را در حافظه پرسرعت خودشان ذخیره میکنند، قابل دسترسی هستند.)
|
توجه این بخش شامل اطلاعات پیشزمینهای در مورد سیستمهای پایگاه داده پیش از پایگاههای رابطهای است. برای آن دسته از خوانندگانی که مشتاقند فقط به SQL بپردازند، میتوانند چند صفحه جلوتر رفته و بخش بعدی را مطالعه کنند. |
در طول چند دهه اول توسعه سیستمهای پایگاههای داده کامپیوتری، دادهها به روشهای مختلفی ذخیره، و به کاربران ارائه داده میشدند. برای مثال، در یک سیستم پایگاه داده سلسله مراتبی (Hierarchical database system)، دادهها به صورت یک یا چند ساختار درختی نمایش داده میشوند. شکل 1-1 نشان میدهد که چگونه دادههای مربوط به حسابهای بانکی دو نفر به نامهای George Blake و Sue Smith میتواند از طریق ساختارهای درختی نمایش داده شوند.
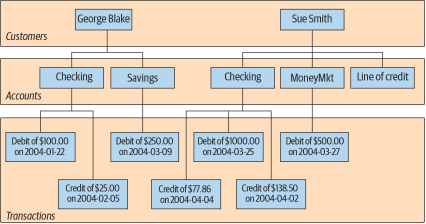
شکل ۱-۱. نمای سلسله مراتبی دادههای حساب
جورج (George) و سو (Sue) هر کدام درخت مخصوص به خود را دارند که شامل حسابهایشان و تراکنشهای مربوط به آن حسابها است. سیستم پایگاه داده سلسله مراتبی برای یافتن درخت یک مشتری خاص، و سپس پیمایش درخت برای یافتن حسابها و/یا تراکنشهای مورد نظر، ابزارهایی را فراهم میکند. هر گره (node) در درخت ممکن است صفر والد، یا یک والد، و همچنین هیچ یا چند فرزند داشته باشد. این پیکربندی به عنوان سلسله مراتب تک-والد (single-parent hierarchy) شناخته میشود.
رویکرد رایج دیگری که وجود دارد، و سیستم پایگاه داده شبکهای (network database system) نامیده میشود، مجموعهای از رکوردها و مجموعهای از پیوندها را نمایش میدهد که روابط بین رکوردهای مختلف را تعریف میکنند. شکل 2-1 نشان میدهد که در چنین سیستمی حسابهای کاربری مشترک جورج و سو چگونه به نظر میرسند.
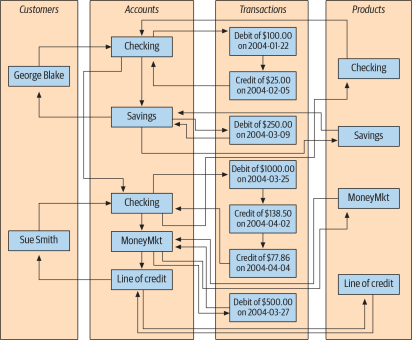
شکل2-1. نمای شبکهای دادههای حساب
برای یافتن تراکنشهای ثبتشده در حساب پول سو، باید مراحل زیر را انجام دهید:
1. رکورد یک مشتری به نام ”سو اسمیت“ را پیدا کنید.
2. لینک موجود در پرونده مشتریان ”سو اسمیت“ را دنبال کنید تا به لیست حسابهای او برسید.
3. زنجیره حسابها را طی کنید تا حساب پول را پیدا کنید.
4. پیوند را از رکورد پول به لیست تراکنشهای آن دنبال کنید.
یکی از ویژگیهای جالب پایگاههای داده شبکهای، توسط مجموعه رکوردهای محصول (product) در سمت راست شکل ۱-۲ نشان داده شده است. توجه داشته باشید که هر رکورد محصول (جاری، پسانداز و غیره) به لیستی از رکوردهای حساب (account) که از آن نوع محصول هستند، اشاره میکند. بنابراین، رکوردهای حساب از چندین مکان (هم رکوردهای مشتری (customer) و هم رکوردهای محصول) قابل دسترسی هستند و به یک پایگاه داده شبکهای اجازه میدهند تا به عنوان یک سلسله مراتبی چند والدی عمل کند.
امروزه هم سیستمهای پایگاه داده سلسله مراتبی و هم شبکهای، زنده و پویا هستند، هرچند آنها عموماً در دنیای کامپیوترهای بزرگ کاربرد دارند. علاوه بر این، سیستمهای پایگاه داده سلسله مراتبی در حوزه سرویسهای دایرکتوری، مانند Active Directory مایکروسافت و Apache Directory Server، دوباره متولد شدهاند . با این حال، از دهه 1970، روش جدیدی برای نمایش دادهها ظاهر شدند، روشی که دقیقتر، و در عین حال، درک و پیادهسازی آن آسان بود.
در سال ۱۹۷۰، دکتر ادگار کاد (Edgar Codd) از آزمایشگاه تحقیقاتی IBM مقالهای با عنوان «مدل رابطهای دادهها برای بانکهای داده بزرگِ مشترک» منتشر کرد که در آن پیشنهاد شده بود دادهها به صورت مجموعهای از جداول (tables) نمایش داده شوند. در این مدل، به جای استفاده از اشارهگرها برای پیمایشِ موجودیتهای مرتبط، از دادههای اضافی برای پیوند دادن رکوردها در جداول مختلف استفاده میشود. شکل 3-1 نشان میدهد که در چنین زمینهای، چگونه اطلاعات حساب جورج و سو نمایش داده میشود.
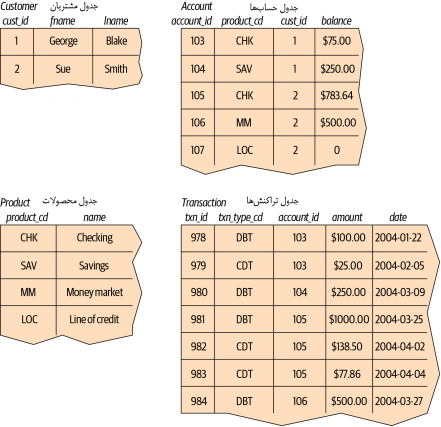
شکل 3-1. نمای رابطهای دادههای حساب
چهار جدول در شکل 3-1، چهار موجودیت که قبلاً مورد بحث قرار گرفتهاند، را نشان میدهند: مشتریان (customer)، محصولات (product)، حسابها (account) و تراکنشها (transaction). با نگاه کردن به بالای جدول مشتری در شکل 3-1، میتوانید سه ستون را ببینید: cust_id (که نشاندهنده شماره شناسایی مشتری است) ، fname (که شامل نام کوچک مشتری است ) و lname (که نشاندهنده نام خانوادگی مشتری است). با نگاه کردن به پایین جدول مشتری، میتوانید دو ردیف را ببینید، یکی حاوی دادههای جورج بلیک و دیگری حاوی دادههای سو اسمیت . تعداد ستونهایی که یک جدول ممکن است داشته باشد، از یک سرور به سرور دیگر متفاوت است، اما به طور کلی به اندازه کافی بزرگ است که مشکلی ایجاد نکند (به عنوان مثال، Microsoft SQL Server در هر جدول تا ۱۰۲۴ ستون را مجاز میداند). تعداد ردیفهایی که یک جدول ممکن است داشته باشد، بیشتر به محدودیتهای فیزیکی (یعنی میزان فضای موجود دیسک) و قابلیت نگهداری (یعنی اینکه یک جدول چقدر میتواند بزرگ شود تا کار با آن دشوار شود) مربوط میشود تا محدودیتهای مربوط به سرور پایگاه داده.
هر جدول در یک پایگاه داده رابطهای شامل اطلاعاتی است که به طور منحصر به فرد یک ردیف را در آن جدول مشخص میکند (که به عنوان کلید اصلی (primary key) شناخته میشود)، همراه با اطلاعات اضافی مورد نیاز برای توصیف کامل موجودیت. با نگاهی دوباره به جدول customer، ستون cust_id برای هر مشتری عدد متفاوتی را در خود جای میدهد. به عنوان مثال، جورج بلیک میتواند به طور منحصر به فرد با شناسه مشتری ۱ شناسایی شود. هرگز به هیچ مشتری دیگری این شناسه اختصاص داده نخواهد شد و هیچ اطلاعات دیگری برای یافتن دادههای جورج بلیک در جدول مشتری لازم نیست.
|
توجه هر سرور پایگاه داده مکانیزمی برای تولید مجموعههای منحصر به فرد از اعداد برای استفاده به عنوان مقادیر کلید اصلی ارائه میدهد، بنابراین نیازی نیست نگران پیگیری اعداد اختصاص داده شده باشید. |
اگرچه میتوانستم از ترکیب ستونهای fname و lname به عنوان کلید اصلی استفاده کنم (کلیدهای اصلی که از دو یا چند ستون تشکیل شده باشند، به عنوان کلیدهای مرکب شناخته میشود)، اما در یک بانک ما به راحتی میتوانیم دو یا چند نفر داشته که هم نام و هم نام خانوادگی آنها یکسان باشند. بنابراین، تصمیم گرفتم ستون cust_id را به طور خاص برای استفاده به عنوان ستون کلید اصلی در جدول مشتری انتخاب کنم.
|
توجه در این مثال، انتخاب fname/lname به عنوان کلید اصلی، به عنوان کلید طبیعی (natural key) شناخته میشود، در حالی که انتخاب cust_id به عنوان کلیدِ جانشین (surrogate key) شناخته میشود. تصمیم گیری در مورد اینکه آیا از کلیدهای طبیعی یا جانشین استفاده شود، به انتخاب طراح پایگاه داده بستگی دارد، اما در این مورد خاص، انتخاب واضح است، زیرا نام خانوادگی یک شخص ممکن است تغییر کند (مانند وقتی که یک زن نام خانوادگی شوهر خود را میگیرد ) و ستونهای کلید اصلی هرگز نباید پس از اختصاص مقدار، تغییر کنند. |
همچنین برخی از جداول شامل اطلاعاتی هستند که برای پیمایشِ جدول دیگری استفاده میشوند؛ اینجاست که «دادههای اضافی» که قبلاً ذکر شد، وارد میشوند. به عنوان مثال، جدول حساب (account) شامل ستونی به نام cust_id است که شامل شناسه منحصر به فرد مشتری که حساب را باز کرده است، به همراه ستونی به نام product_cd است که شامل شناسه منحصر به فرد محصولی (product) است که حساب با آن مطابقت خواهد داشت. این ستونها به عنوان کلیدهای خارجی (foreign keys) شناخته میشوند و مانند همان خطوطی هسنند که در نسخههای سلسله مراتبی و شبکهای اطلاعات حساب موجودیتها را به هم متصل میکنند. اگر به یک رکورد حسابِ خاص نگاه میکنید و میخواهید اطلاعات بیشتری در مورد مشتری که حساب را باز کرده را بدانید، مقدار ستون cust_id را میگیرید و از آن برای یافتن ردیف مناسب در جدول مشتری استفاده میکنید (این فرآیند، در زبان پایگاه داده رابطهای، به عنوان اتصال (join) شناخته میشود؛ اتصالها در فصل 3 معرفی میشوند و در فصلهای 5 و 10 به طور عمیق بررسی شدهاند).
ممکن است ذخیره چندین باره دادههای یکسان، اسراف به نظر برسد، اما در مدل رابطهای دلیل اینکه چه دادههای اضافی باید ذخیره شوند، کاملاً واضح است. به عنوان مثال، مناسب است که جدول account شامل ستونی برای شناسه منحصر به فرد یک مشتری که حساب را باز کرده است، باشد، اما مناسب نیست که نام و نام خانوادگی مشتری را نیز در جدول حساب قرار دهید. به عنوان مثال، اگر قرار باشد مشتری نام خود را تغییر دهد، باید مطمئن شوید که فقط یک مکان در پایگاه داده وجود دارد که نام مشتری را در خود نگه میدارد. در غیر این صورت، ممکن است دادهها در یک مکان تغییر کنند اما در مکان دیگر تغییر نکنند و باعث شوند که دادههای موجود در پایگاه داده غیرقابل اعتماد شوند. مکان مناسب برای این دادهها جدول مشتریان (customer) است و فقط مقادیر cust_id باید در جداول دیگر گنجانده شوند. همچنین مناسب نیست که یک ستون واحد شامل چندین قطعه اطلاعات باشد، مانند ستون نام، که شامل نام و نام خانوادگی یک شخص است، یا ستون آدرس که شامل اطلاعات خیابان، شهر، استان و کد پستی است. فرآیند اصلاح طراحی پایگاه داده برای اطمینان از اینکه هر قطعه اطلاعات مستقل (به جز کلیدهای خارجی) فقط در یک مکان قرار گیرد به عنوان نرمالسازی (normalization) شناخته میشود.
با بازگشت به چهار جدولِ شکل 3-1 ممکن است از خود بپرسید که چگونه میتوانید از این جداول برای یافتن تراکنشهای حساب جاری جورج بلیک استفاده کنید. برای اینکار ابتدا شناسه منحصر به فرد جورج بلیک را در جدول مشتری پیدا میکنید. سپس در جدول حسابها (account) ردیفی را پیدا میکنید که ستون cust_id آن حاوی شناسه منحصر به فرد جورج است و ستون product_cd آن با ردیفی در جدول محصول که ستون name آن با «Checking» مطابقت داشته باشد. در نهایت، ردیفهایی را در جدول تراکنش پیدا میکنید که ستون account_id آنها با شناسه منحصر به فرد جدول حساب مطابقت دارد. این ممکن است پیچیده به نظر برسد، اما همانطور که به زودی خواهید دید، میتوانید این کار را با استفاده از زبان SQL، تنها با یک دستور واحد انجام دهید.
من در بخشهای قبلی برخی اصطلاحات جدید را معرفی کردم، بنابراین شاید وقت آن رسیده باشد که تعاریف رسمی آنها را ارائه دهیم. جدول ۱-۱ اصطلاحاتی را که در ادامه کتاب استفاده میکنیم به همراه تعاریف آنها نشان میدهد.
|
اصطلاح |
تعریف |
|
نهاد (Entity) |
چیزی که برای جامعه کاربران پایگاه داده جالب باشد. مثلاً مشتریان، قطعات، موقعیتهای جغرافیایی و غیره. |
|
ستون (Column) |
یک قطعه داده جداگانه که در یک جدول ذخیره شده است. |
|
ردیف (Row) |
مجموعهای از ستونها که با هم به طور کامل یک موجودیت یا عملی روی یک موجودیت را توصیف میکنند. یک ردیف یک رکورد نیز نامیده میشود. |
|
جدول (Table) |
مجموعهای از ردیفها، که یا در حافظه (غیرپایدار) و یا در حافظه دائمی (پایدار) نگهداری میشوند. |
|
مجموعه نتایج (Result set) |
نام دیگری برای جدول غیرپایدار، که عموماً نتیجه یک پرسوجوی SQL هستند. |
|
کلید اصلی (Primary Key) |
یک یا چند ستون که میتوانند به عنوان شناسه منحصر به فرد برای هر سطر در یک جدول استفاده شوند. |
|
کلید خارجی (Foreign key) |
یک یا چند ستون که میتوانند با هم برای شناسایی یک ردیف واحد در جدول دیگر استفاده شوند. |
جدول ۱-۱. اصطلاحات و تعاریف
در تعریف ادگار کاد از مدل رابطهای، او را برای دستکاری دادهها در جداول رابطهای، زبانی به نام DSL/Alpha را پیشنهاد داد. کمی پس از انتشار مقاله کاد، شرکت IBM بر اساس ایدههای او گروهی را مأمور پیادهسازی اولیهای این زبان کرد. این گروه نسخه سادهشدهای از DSL/Alpha را ایجاد کردند که آن را SQUARE نامیدند. اصلاحات SQUARE منجر به زبانی به نام SEQUEL شد که در نهایت به اختصار SQL نامیده شد. هرچند SQL به عنوان زبانی برای دستکاری دادهها در پایگاههای داده رابطهای کارش را شروع کرد، ولی (همانطور که در انتهای این کتاب خواهید دید) حالا به زبانی برای دستکاری دادهها در فناوریهای مختلف پایگاه داده تبدیل شده است.
حالا SQL بیش از 50 سال است که قدمت دارد و در طول این مسیر دستخوش تغییرات زیادی شده است. در اواسط دهه ۱۹۸۰، موسسه ملی استاندارد آمریکا (ANSI) کار بر روی اولین استانداردِ زبان SQL را آغاز کرد که در سال ۱۹۸۶ منتشر شد. اصلاحات بعدی منجر به انتشار نسخههای جدید استاندارد SQL در سالهای ۱۹۸۹، ۱۹۹۲، ۱۹۹۹، ۲۰۰۳، ۲۰۰۶، ۲۰۰۸، ۲۰۱۱ و ۲۰۱۶ شد. در کنار اصلاحات زبان اصلی، ویژگیهای جدیدی به زبان SQL اضافه شده است تا قابلیتهای شیگرا را نیز در خود جای دهد. استانداردهای بعدی بر ادغام فناوریهای مرتبط، مانند زبان نشانهگذاری توسعهپذیر (XML) و نمادگذاری شیء جاوا اسکریپت (JSON) تمرکز دارند.
SQL با مدل رابطهای همراه است، زیرا نتیجه یک پرسوجوی SQL یک جدول است (که در این زمینه، مجموعه نتایج نیز نامیده میشود). بنابراین، در یک پایگاه داده رابطهای میتوان با ذخیره مجموعه نتایج یک پرسوجو، یک جدول دائمی جدید را ایجاد کرد. به طور مشابه، یک پرسوجو میتواند هم از جداول دائمی و هم از مجموعه نتایج پرسوجوهای دیگر به عنوان ورودی استفاده کند (ما این موضوع را به تفصیل در فصل 9 بررسی خواهیم کرد).
نکته آخر: SQL مخفف هیچ چیزی نیست (اگرچه بسیاری از مردم اصرار دارند که مخفف « زبان پرسوجوی ساختاریافته » است). هنگام اشاره به این زبان، میتوان حروف را به صورت جداگانه (مثلاً SQL) یا به صورت دنبالهدار بیان کرد.
زبان SQL به چندین بخش مجزا تقسیم میشود: بخشهایی که در این کتاب بررسی میکنیم شامل دستورات طرحواره (schema statement) SQL است که برای تعریف ساختارهای داده ذخیره شده در پایگاه داده استفاده میشوند؛ دستورات داده (data statements) SQL که برای دستکاری ساختارهای داده که قبلاً با استفاده از دستورات طرحواره SQL تعریف شدهاند استفاده میشوند؛ و دستورات تراکنش (transaction statements) SQL که برای شروع، پایان، و بازگرداندن تراکنشها استفاده میشوند (این مفاهیم در فصل 12 مطرح میشوند). به عنوان مثال، برای ایجاد یک جدول جدید در پایگاه داده خود، از یک دستور طرحواره SQL به نام create table استفاده میکنید، در حالی که فرآیند پر کردن این جدول جدید با دادهها، به یک دستور داده SQL به نام insert نیاز دارد.
برای اینکه تصوری از ظاهر این دستورات داشته باشید، در اینجا یک دستور طرحواره SQL را مشاهده میکنید که جدولی به نام corporation ایجاد میکند:

این دستور یک جدول با دو ستون corp_id و name ایجاد میکند که ستون corp_id به عنوان کلید اصلی جدول مشخص شده. جزئیات دقیقتر این دستور، مثل انواع دادههای مختلف موجود در MySQL، را در فصل 2 بررسی خواهیم کرد. در زیر یک دستور داده SQL آمده که در جدول Corporation ردیفی به نام ‘Acme Paper’ را درج میکند:

این دستور یک ردیف را به جدول corporation اضافه میکند، که مقدار ستون corp_id 27، و مقدار ستون name 'Acme Paper Corporation' است.
در نهایت، در اینجا برای بازیابی دادههایی که تازه درج شدهاند یک دستور select ساده آمده است :

تمام عناصر پایگاه داده که از طریق دستورات طرحواره SQL ایجاد میشوند، در مجموعهای خاص از جداول به نام واژهنامه داده (data dictionary) ذخیره میشوند. این «دادههای مربوط به پایگاه داده» کلاً به عنوان فراداده (metadata) شناخته میشوند و در فصل ۱۵ بررسی میشوند. درست مانند جداولی که خودتان ایجاد میکنید، جداول واژهنامه داده را میتوان از طریق یک دستور select جستجو کرد و از این طریق شما میتوانید در زمان اجرا برنامه ساختار دادههای فعلی مستقر در پایگاه داده را مشخص کنید. به عنوان مثال، اگر از شما خواسته شود گزارشی بنویسید که حسابهای جدید ایجاد شده در ماه گذشته را نشان دهد، میتوانید نام ستونهای جدول حساب را که هنگام نوشتن گزارش برای شما شناخته شده بودند، به صورت کدنویسیسخت (hardcode) بنویسید، یا از فرهنگ داده برای تعیین مجموعه ستونهای فعلی پرسوجو کنید و هر بار که گزارش اجرا میشود، به صورت پویا آن را تولید کنید.
بیشتر این کتاب مربوط به بخش داده زبان SQL است که شامل دستورات انتخاب، بهروزرسانی، درج و حذف دادهها میشود. دستورات طرحواره SQL در فصل 2 نشان داده شدهاند، و شما را در طراحی و ایجاد برخی جداول ساده راهنمایی میکنند. به طور کلی، دستورات طرحواره SQL جدا از نحوِ دستوری خودشان به توضیح زیادی نیاز ندارند، در حالی که دستورات داده SQL، اگرچه تعداد آنها کم است، اما فرصتهای بیشماری را برای مطالعه دقیق ارائه میدهند. بنابراین، در حالی که من تلاش دارم شما را با بسیاری از دستورات طرحواره SQL آشنا کنم، بیشتر فصلهای این کتاب بر دستورات داده SQL تمرکز دارند.
اگر در گذشته با زبانهای برنامهنویسی کار کرده باشید، به تعریف متغیرها و ساختارهای داده، استفاده از منطق شرطی (یعنی if-then-else) و ساختارهای حلقهای (یعنی do while ... end) و تقسیم برنامه خود به قطعات کوچک و قابل استفاده مجدد (یعنی اشیاء، توابع، رویهها) عادت دارید. کُد شما به یک کامپایلر تحویل داده میشود و فایل اجرایی حاصل دقیقاً کاری را که برای آن برنامهریزی کردهاید، انجام میدهد (البته نه همیشه). چه با Java، Python، Scala، یا هر زبان رویهای (procedural) دیگری کار کنید، کنترل کامل عملکرد برنامه را در دست دارید.

ولی در SQL باید از برخی از کنترلهایی که به آنها عادت دارید، صرف نظر کنید، زیرا دستورات SQL ورودیها و خروجیهای لازم را تعریف میکنند، اما نحوه اجرای یک دستور به بخشی از موتور پایگاه داده واگذار میشود که به عنوان بهینهساز (optimizer) شناخته میشود. وظیفه بهینهساز این است که دستورات SQL شما را بررسی کند و با در نظر گرفتن نحوه پیکربندی جداول شما، و اینکه چه شاخصهایی (indexes) در دسترس هستند، کارآمدترین مسیر اجرا (البته نه همیشه کارآمدترین) را تعیین کند. اکثر موتورهای پایگاه داده به شما این امکان را میدهند که با مشخص کردن نکات بهینهساز، مانند پیشنهاد استفاده از یک شاخص خاص، بر تصمیمات بهینهساز تأثیر بگذارید. با این حال، اکثر کاربران SQL هرگز به این سطح از پیچیدگی نمیرسند و چنین تغییراتی را به مدیر پایگاه داده یا کارشناسان خود واگذار میکنند.
بنابراین، در SQL شما قادر به نوشتن برنامههای کامل نخواهید بود. مگر اینکه در حال نوشتن یک اسکریپت ساده برای دستکاری دادههای خاص باشید، باید SQL را با زبان برنامهنویسی مورد علاقه خود ادغام کنید. برخی از تولیدکنندگان پایگاه داده این کار را برای شما انجام دادهاند، مانند زبان PL/SQL اوراکل، زبان رویه ذخیره شده MySQL و زبان Transact-SQL مایکروسافت. در این زبانها، دستورات داده SQL بخشی از گرامر زبان هستند و به شما امکان میدهند به طور یکپارچه پرسوجوهای پایگاه داده را با دستورات رویهای ادغام کنید. با این حال، اگر از زبانی غیرمرتبط با پایگاه داده، مثل جاوا یا پایتون، استفاده میکنید، برای اجرای دستورات SQL از داخل برنامه خودتان باید از یک جعبه ابزار یا API استفاده کنید. برخی از این جعبه ابزارها توسط تولیدکنندگان پایگاه داده ارائه میشوند، در حالی که برخی دیگر توسط شرکتهای شخص ثالث یا ارائه دهندگان منبع باز ساخته میشوند. جدول2-1 برخی از گزینههای موجود برای ادغام SQL در یک زبان خاص را نشان میدهد.
|
زبان |
جعبه ابزار |
|
Java |
JDBC (اتصال به پایگاه داده جاوا) |
|
C# |
ADO.NET (مایکروسافت) |
|
Ruby |
Ruby DBI |
|
Python |
Python DB |
|
Go |
Package database/sql |
جدول 2-1. جعبه ابزارهای یکپارچهسازی SQL
اگر فقط به اجرای تعاملی دستورات SQL نیاز دارید، هر تولیدکننده پایگاه داده حداقل یک ابزار خط فرمانی ساده برای ارسال دستورات SQL به موتور پایگاه داده و بررسی نتایج ارائه میدهد. اکثر فروشندگان یک ابزار گرافیکی نیز ارائه میدهند که شامل یک پنجره برای وارد کردن دستورات SQL، و یک پنجره دیگر برای نمایش نتایج حاصل از دستورات SQL است. علاوه بر این، ابزارهای شخص ثالثی مانند SQuirrel وجود دارند که از طریق اتصال JDBC به سرورهای پایگاه داده مختلف متصل میشوند. از آنجایی که مثالهای این کتاب بر روی پایگاه داده MySQL اجرا میشوند، من برای اجرای مثالها و قالببندی نتایج، از ابزار خط فرمان mysql، که به عنوان بخشی از نصب MySQL موجود است، استفاده میکنم.
قبلاً در همین فصل قول داده بودم که یک دستور SQL را به شما نشان دهم که تمام تراکنشهای مربوط به حساب جاری George Blake را برمیگرداند. این دستور به شکل زیر است:
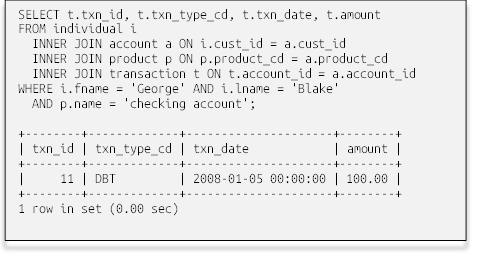
بدون اینکه در این مرحله وارد جزئیات زیادی شویم، این پرسوجو ردیف جدول individual برای جورج بلیک، و ردیف جدول product را برای محصول «checking» شناسایی میکند، ردیف جدول account را برای این ترکیب فرد/محصول پیدا میکند و چهار ستون از جدول transaction را برای همه تراکنشهای ارسال شده به این حساب برمیگرداند. اگر بدانید که شناسه مشتری جورج بلیک ۸ است و حسابهای جاری با کد 'CHK' مشخص شدهاند، به سادگی میتوانید بر اساس شناسه مشتری حساب جاری جورج بلیک را در جدول حسابها پیدا کنید و از شناسه حساب برای یافتن تراکنشهای مناسب استفاده کنید:

من در فصلهای بعدی تمام مفاهیم موجود در این پرسوجوها (و همچنین موارد بسیار بیشتری) را توضیح خواهم داد، اما حداقل میخواستم نشان دهم که آنها چگونه به نظر میرسند.
پرسوجوهای قبلی شامل سه بندِ (clauses) مختلف بودند: select، from و where. تقریباً هر پرسوجویی که با آن مواجه میشوید، حداقل شامل این سه عبارت خواهد بود، اگرچه چندین عبارت دیگر نیز وجود دارد که میتوانید برای اهداف تخصصیتر از آنها استفاده کنید. نقش هر یک از این سه عبارت در موارد زیر نشان داده شده است:


عموماً هنگام ساخت پرسوجو، اولین وظیفه شما تعیین جدول یا جداول مورد نیاز و سپس اضافه کردن آنها به بندِ from است. در مرحله بعد، باید شرایطی را به بندِ where اضافه کنید تا دادههایی را که به آنها علاقهای ندارید از این جداول فیلتر کنید. در نهایت، تصمیم میگیرید که کدام ستونها از جداول مختلف باید بازیابی شوند و آنها را به بندِ select خود اضافه کنید. در اینجا یک مثال ساده وجود دارد که نشان میدهد چگونه میتوانید همه مشتریان که نام خانوادگی آنها "Smith" است را پیدا کنید :

این پرسوجو یک جدول تک را برای تمام ردیفهایی که ستون lname آنها با رشته 'Smith' مطابقت دارد جستجو میکند و ستونهای cust_id و fname را از آن ردیفها برمیگرداند.
همراه با پرسوجو از پایگاه داده، شما به احتمال زیاد درگیر پر کردن و تغییر دادهها در پایگاه داده خود نیز خواهید بود. در اینجا یک مثال ساده از نحوه اضافه کردن یک ردیف جدید به جدول product آورده شده است:
![]()
اوه به نظر میرسد شما لغت « Deposit» رو به اشتباه ’ Depysit'وارد کردهاید. مشکلی نیست . شما میتونید آن را با یه دستور update تصحیح کنید:

توجه داشته باشید که دستور update نیز مانند دستور select شامل یک بندِ where است. دلیل این امر آن است که یک دستور update باید ردیفهایی که باید اصلاح شوند، را شناسایی کند. در این حالت، شما مشخص میکنید که فقط ردیفهایی که ستون product_cd آنها با رشته 'CD' مطابقت دارد، باید اصلاح شوند. از آنجایی که ستون product_cd کلید اصلی جدول product است، باید انتظار داشته باشید که دستور update شما دقیقاً یک ردیف (یا اگر مقداری در جدول وجود نداشته باشد، صفر ردیف) را تصحیح کند . هر زمان که یک دستور داده SQL را اجرا میکنید، از موتور پایگاه داده بازخوردی در مورد تعداد ردیفهایی که تحت تأثیر دستور شما قرار گرفتهاند، دریافت خواهید کرد. اگر از یک ابزار تعاملی مانند ابزار خط فرمان mysql که قبلاً ذکر شد استفاده میکنید، در مورد تعداد ردیفها بازخوردی دریافت خواهید کرد:
· تعداد ردیفهایی که توسط دستور select برگردانده میشود
· تعداد ردیفها که توسط دستور insert ایجاد میشود
· تعداد ردیفهایی که توسط دستور update اصلاح میشود
· تعداد ردیفهایی که با دستور delete حذف میشود
اگر از یک زبان رویهای با یکی از ابزارهای ذکر شده قبلی استفاده میکنید، این ابزار شامل فراخوانی برای درخواست این اطلاعات پس از اجرای دستور داده SQL خواهد بود. به طور کلی این ایده خوبی خواهد بود که این اطلاعات را بررسی کنید تا مطمئن شوید که دستور شما کار غیرمنتظرهای انجام نداده است (مثلاً وقتی فراموش کردهاید یک بندِ where را در دستور delete خود قرار دهید و تمام سطرهای جدول را حذف کنید!).
پایگاههای داده رابطهای بیش از سه دهه است که به صورت تجاری در دسترس هستند. برخی از کاملترین و محبوبترین محصولات تجاری عبارتند از:
· پایگاه داده Oracle ساخته شرکت اوراکل
· SQL Server ساخته شرکت مایکروسافت
· پایگاه داده عمومی DB2 ساخته شرکت IBM
همه این سرورهای پایگاه داده تقریباً کار مشابهی انجام میدهند، اگرچه برخی از آنها برای اجرای پایگاههای داده بسیار بزرگ، یا با توان عملیاتی بسیار بالا مناسبتر هستند. برخی دیگر در مدیریت اشیاء یا فایلهای بسیار بزرگ یا اسناد XML و غیره بهتر عمل میکنند. علاوه بر این، همه این سرورها در رعایت آخرین استانداردهای ANSI SQL عملکرد بسیار خوبی دارند. این چیز خوبی است و من این نکته را به شما نشان میدهم که چگونه دستورات SQL را بنویسید تا بتوانید با کمی تغییر، یا بدون تغییر، روی هر یک از این پلتفرمها آنها را اجرا کنید.
در کنار سرورهای پایگاه داده تجاری، در دو دهه گذشته در جامعه متنباز فعالیتهای زیادی با هدف ایجاد یک جایگزین مناسب برای محصولات مذکور صورت گرفته است. دو مورد از رایجترین سرورهای پایگاه داده متنباز، PostgreSQL و MySQL هستند. سرور MySQL به صورت رایگان در دسترس است و به نظرم دانلود و نصب آن بسیار ساده است. به همین دلایل، تصمیم گرفتهام که تمام مثالهای این کتاب روی یک پایگاه داده MySQL (نسخه ۸.۰) اجرا شوند و از ابزار خط فرمان mysql برای قالببندی نتایج پرسوجو استفاده شود. حتی اگر در حال حاضر از سرور دیگری استفاده میکنید و هرگز قصد استفاده از MySQL را ندارید، از شما میخواهم که آخرین نسخه سرور MySQL را نصب کنید، طرحواره و دادههای نمونه را بارگذاری کنید و آن را با دادهها و مثالهای این کتاب آزمایش کنید.
ولی هشدار زیر را در نظر داشته باشید:
این کتاب درباره پیادهسازی SQL در MySQL نیست .
بلکه این کتاب به گونهای طراحی شده است که به شما نحوهی نوشتن دستورات SQL را آموزش دهد که بدون هیچ تغییری روی MySQL اجرا شوند و همچنین با تغییرات اندک، یا بدون هیچ تغییری، روی نسخههای جدید پایگاه داده Oracle، DB2 و SQL Server اجرا شوند.
در طول ده سال میان ویرایش دوم و سوم این کتاب، اتفاقات زیادی در دنیای پایگاه داده رخ داده است. در حالی که پایگاههای داده رابطهای هنوز به طور گسترده مورد استفاده قرار میگیرند و این روند تا مدتی نیز ادامه خواهند داشت، برای برطرف کردن نیازهای شرکتهایی مانند آمازون و گوگل، فناوریهای جدید پایگاه داده ظهور کردهاند. این فناوریها شامل Hadoop، Spark، NoSQL و NewSQL هستند که سیستمهای توزیعشده و مقیاسپذیر هستند که معمولاً روی خوشههایی از سرورهای معمولی مستقر میشوند. اگرچه بررسی دقیق این فناوریها فراتر از محدوده این کتاب است، اما همه آنها وجه مشترکی با پایگاههای داده رابطهای دارند، و آن هم استفاده از زبان SQL است.
از آنجایی که سازمانها اغلب دادهها را با استفاده از چندین فناوری ذخیره میکنند، نیاز به جدا کردن SQL از یک سرور پایگاه داده خاص و ارائه سرویسی است که بتواند چندین پایگاه داده را در بر بگیرد. به عنوان مثال، یک گزارش ممکن است نیاز به گردآوری دادههای ذخیره شده در Oracle، Hadoop، فایلهای JSON، فایلهای CSV و فایلهای ثبت وقایع Unix داشته باشد. برای مقابله با این نوع چالشها نسل جدیدی از ابزارها ساخته شدهاند و یکی از امیدوارکنندهترین آنها Apache Drill است که یک موتور پرسوجوی متنباز است و به کاربران امکان میدهد پرسوجوهایی را بنویسند که بتوانند به دادههای ذخیره شده در تقریباً هر پایگاه داده یا سیستم فایلی دسترسی داشته باشند. ما Apache Drill را در فصل 18 بررسی خواهیم کرد.
هدف کلی چهار فصل بعدی، معرفی دستورات داده SQL، با تأکید ویژه بر سه بندِ اصلی دستور select است. علاوه بر این، مثالهای زیادی را خواهید دید که از طرحواره Sakila (که در فصل بعدی معرفی میشود) استفاده میکنند، و برای همه مثالهای کتاب از آنها استفاده خواهد شد. امید من این است که آشنایی با یک پایگاه داده واحد به شما این امکان را بدهد که هر بار بدون نیاز به توقف و بررسی جداول مورد استفاده، به اصل نکته مثالها برسید. اگر کار با همان مجموعه جداول کمی خستهکننده شد، میتوانید پایگاه داده نمونه را با جداول اضافی تکمیل کنید یا پایگاه داده خودتان را برای آزمایش ایجاد کنید.
پس از اینکه به خوبی اصول اولیه را فرا گرفتید، فصلهای باقیمانده به مفاهیم اضافیِ عمیقتر میپردازند، که اکثر آنها مستقل از یکدیگر هستند. بنابراین، اگر احساس سردرگمی کردید، همیشه میتوانید به جلو بروید و بعداً برگردید تا یک فصل را دوباره مرور کنید. وقتی کتاب را تمام کردید و تمام مثالها را حل کردید، در مسیر تبدیل شدن به یک متخصص SQL باتجربه قرار خواهید گرفت.
برای خوانندگانی که علاقهمند به کسب اطلاعات بیشتر در مورد پایگاههای داده رابطهای، تاریخچه سیستمهای پایگاه داده کامپیوتری یا زبان SQL هستند، در اینجا چند منبع ارزشمند برای بررسی ارائه شده است:
· Database in Depth: Relational Theory for Practitioners by C. J. Date (O’Reilly)
· An Introduction to Database Systems, Eighth Edition, by C. J. Date (Addison-Wesley)
· The Database Relational Model: A Retrospective Review and Analysis, by C. J. Date (Addison-Wesley)
· مقاله ویکیپدیا در مورد تعریف « سیستم مدیریت پایگاه داده»
...........................................
محتویات کامل این کتاب در 18 فصل و 550 صفحه منتشر شده، برای ادامه مطالعه این کتاب میتوانید نسخه کامل PDF آن را تهیه کنید.
این فصل اطلاعات مورد نیاز برای ایجاد یک پایگاه داده و ایجاد جداول و دادههای مرتبط با آن، که برای مثالهای این کتاب از آنها استفاده میشوند، را در اختیار شما قرار میدهد. شما همچنین با انواع مختلف دادهها آشنا خواهید شد و نحوه ایجاد جداول با استفاده از آنها را خواهید دید. از آنجا که مثالهای این کتاب بر روی یک پایگاه داده MySQL اجرا میشوند، این فصل تا حدودی به سمت ویژگیها و نحوه دستورات MySQL متمایل است، اما اکثر مفاهیم برای بیشتر سرورها قابل اجرا هستند.
اگر میخواهید بتوانید با دادههای استفاده شده برای مثالهای این کتاب آزمایش کنید، دو گزینه دارید:
سرور MySQL نسخه ۸.۰ (یا بالاتر) را دانلود و نصب کنید و پایگاه داده نمونه Sakila را از
https://dev.mysql.com/doc/index-other.html
بارگذاری کنید.
برای دسترسی به MySQL Sandbox به آدرس
https://www.katacoda.com/mysql-db-sandbox/scenarios/mysql-sandbox
بروید، که پایگاه داده نمونه Sakila را در یک نمونه MySQL بارگذاری کرده است. شما باید یک حساب کاربری (رایگان) Katacoda ایجاد کنید. سپس، روی دکمه Start Scenario کلیک کنید.
اگر گزینه دوم را انتخاب کنید، به محض شروع سناریو، یک سرور MySQL نصب و راهاندازی میشود و سپس طرح و دادههای Sakila بارگذاری میشوند. وقتی آماده شد، یک اعلان استاندارد mysql> ظاهر میشود که بعد از آن میتوانید شروع به پرسوجو از پایگاه داده نمونه کنید. این قطعاً سادهترین گزینه است و پیشبینی میکنم که اکثر خوانندگان این گزینه را انتخاب کنند. اگر این گزینه برای شما مناسب به نظر میرسد، میتوانید به بخش بعدی بروید.
اگر ترجیح میدهید کپی خودتان از دادهها را داشته باشید و میخواهید تغییراتی که ایجاد کردهاید دائمی باشند، یا اگر فقط علاقهمند به نصب سرور MySQL روی دستگاه خودتان هستید، ممکن است گزینه اول را ترجیح دهید. همچنین میتوانید از یک سرور MySQL که در محیطی مانند Amazon Web Services یا Google Cloud میزبانی میشود، استفاده کنید. در هر صورت، خودتان باید نصب/پیکربندی را انجام دهید، زیرا اینکار فراتر از محدوده این کتاب است. پس از در دسترس بودن پایگاه داده، باید چند مرحله را برای بارگیری پایگاه داده نمونه Sakila دنبال کنید.
ابتدا باید کلاینت خط فرمان mysql را اجرا کنید و یک رمز عبور وارد کنید، و سپس مراحل زیر را انجام دهید:
به آدرس
https://dev.mysql.com/doc/index-other.html
بروید و فایلهای مربوط به «پایگاه داده sakila » را از بخش «پایگاههای داده نمونه» دانلود کنید.
فایلها را در یک دایرکتوری محلی مانند C:\temp\sakila-db قرار دهید (برای دو مرحله بعدی استفاده میشود، اما آن را با مسیر دایرکتوری خود جایگزین کنید).
عبارت
source c:\temp\sakila-db\sakila-schema.sql را تایپ کرده و Enter را بزنید.
عبارت
source c:\temp\sakila-db\sakila-data.sql را تایپ کنید. و Enter را فشار دهید.
اکنون باید یک پایگاه داده فعال داشته باشید که تمام دادههای مورد نیاز برای مثالهای این کتاب را در خود جای داده باشد.

اگر از یک نشست موقت پایگاه داده (گزینه دوم در بخش قبل) استفاده نکنید، برای تعامل با پایگاه داده باید ابزارِ خط فرمان mysql را اجرا کنید. برای انجام این کار، باید یک پوسته ویندوز یا یونیکس را باز کنید و ابزار mysql را اجرا کنید. به عنوان مثال، اگر با استفاده از حساب کاربری root وارد سیستم میشوید، باید موارد زیر را انجام دهید:
![]()
سپس از شما رمز عبورتان پرسیده میشود و پس از آن، اعلان mysql> را مشاهده خواهید کرد. برای مشاهدهی تمام پایگاههای دادهی موجود، میتوانید از دستور زیر استفاده کنید:
از آنجایی که شما از پایگاه داده Sakila استفاده خواهید کرد، باید پایگاه دادهای را که میخواهید با آن کار کنید از طریق دستور use مشخص کنید:
![]()
هر زمان که ابزار خط فرمان mysql را فراخوانی میکنید، میتوانید مانند زیر نام کاربری و پایگاه داده مورد استفاده را مشخص کنید:
![]()
این کار باعث میشود هر بار که ابزار را اجرا میکنید، دیگر مجبور نباشید عبارت use sakila را تایپ کنید. اکنون که یک جلسه (session) ایجاد کرده و پایگاه داده را مشخص کردهاید، میتوانید دستورات SQL را اجرا کرده و نتایج را مشاهده کنید. به عنوان مثال، اگر میخواهید تاریخ و زمان فعلی را بدانید، میتوانید پرسوجو زیر را اجرا کنید:

تابع ()now یک تابع درونی MySQL است که تاریخ و زمان فعلی را برمیگرداند. همانطور که میبینید، ابزار خط فرمان mysql نتایج پرسوجوهای شما را در یک مستطیل که با حرفهای +، - و | محدود شده است، قالببندی میکند. پس از اتمام نتایج (که در این مورد، فقط یک ردیف از نتایج وجود دارد)، ابزار خط فرمان mysql تعداد ردیفهای برگردانده شده و همچنین مدت زمان اجرای دستور SQL را نشان میدهد.

وقتی کارتان با ابزار خط فرمان mysql تمام شد، کافیست quit; یا exit; را تایپ کنید تا به پوسته فرمان یونیکس یا ویندوز برگردید.
به طور کلی، همه سرورهای پایگاه داده رایج، قابلیت ذخیره انواع دادههای یکسان، مانند رشتهها، تاریخها، و اعداد را دارند. جایی که معمولاً آنها با هم متفاوت هستند، در انواع دادههای تخصصی، مانند اسناد XML و JSON، یا دادههای مکانی است. از آنجایی که این یک کتاب مقدماتی در مورد SQL است و از آنجایی که 98٪ ستونهایی که با آنها مواجه میشوید، انواع دادههای ساده هستند، این فصل فقط انواع دادههای حرفی، تاریخی (زمانی)، و عددی را پوشش میدهد. استفاده از SQL برای پرسوجو از اسناد JSON در فصل 18 بررسی خواهد شد.
دادههای حرفی میتوانند به صورت رشتههایی با طول ثابت یا متغیر ذخیره شوند. تفاوت این است که رشتهها با طول ثابت با فاصله از راست پر میشوند و همیشه تعداد بایتهای یکسانی مصرف میکنند، ولی رشتهها با طول متغیر با فاصله از راست پر نمیشوند و همیشه تعداد بایتهای یکسانی مصرف نمیکنند. هنگام تعریف یک ستون حرفی، باید حداکثر اندازه هر رشتهای که قرار است در ستون ذخیره شود، را مشخص کنید. به عنوان مثال، اگر میخواهید رشتههایی با طول حداکثر 20 حرف را ذخیره کنید، میتوانید از هر یک از تعاریف زیر استفاده کنید:
![]()
در حال حاضر حداکثر طول ستونهای char ۲۵۵ بایت است، در حالی که طول ستونهای varchar میتوانند تا ۶۵۵۳۵ بایت باشند. اگر نیاز به ذخیره رشتههای طولانیتر (مانند ایمیلها، اسناد XML و غیره) دارید، باید از یکی از گونههای متن (mediumtext و longtext) استفاده کنید که بعداً در این بخش به آنها خواهم پرداخت. به طور کلی، وقتی تمام رشتههایی که در ستون ذخیره میشوند قرار است طول یکسانی داشته باشند، مانند نام اختصاری ایالتها، باید از گونه char، و وقتی رشتههایی که قرار است در ستون ذخیره شوند طولهای متفاوتی دارند، باید از نوع varchar استفاده کنید. هر دو گونه char و varchar به روشی مشابه در تمام سرورهای پایگاه داده اصلی استفاده میشوند.

برای زبانهایی که از الفبای لاتین استفاده میکنند، مانند انگلیسی، تعداد حروف آنها کم است، و برای ذخیره هر حرف فقط به یک بایت نیاز است. زبانهای دیگر، مانند ژاپنی و کرهای، تعداد زیادی حرف دارند، بنابراین برای ذخیره هر حرف به چندین بایت حافظه نیاز دارند. بنابراین، چنین مجموعه حروفی، مجموعه حروف چند بایتی (multibyte character sets) نامیده میشوند.
MySQL میتواند دادهها را با استفاده از مجموعه حرفهای مختلف، چه تک بایتی و چه چند بایتی، ذخیره کند. همانطور که در مثال زیر نشان داده شده، برای مشاهده مجموعه حرفهای پشتیبانی شده در سرور خود، میتوانید از دستور show استفاده کنید:
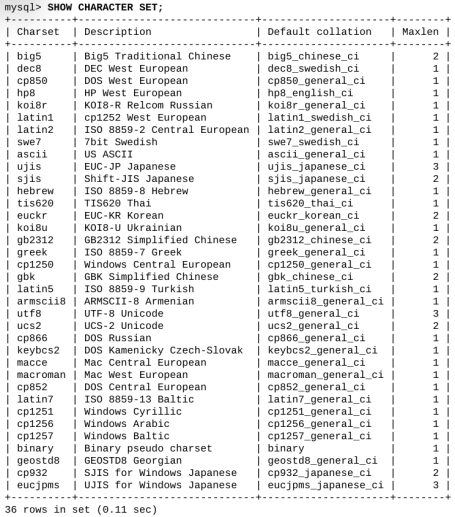
اگر مقدار ستون چهارم، یعنی maxlen، بزرگتر از ۱ باشد، آنگاه این مجموعه حرف یک مجموعه حرف چند بایتی است.
در نسخههای قبلی سرور MySQL، مجموعه حرفی latin1 به طور خودکار به عنوان مجموعه حرفی پیشفرض انتخاب میشد، اما در نسخه ۸ به طور پیشفرض روی utf8mb4 تنظیم شده است. با این حال، میتوانید برای هر ستون حرفی در پایگاه داده خود از یک مجموعه حرفی متفاوت استفاده کنید و حتی میتوانید مجموعه حرفهای مختلفی را در یک جدول ذخیره کنید. برای انتخاب یک مجموعه حرفی غیر از مجموعه حرفی پیشفرض، کافیست هنگام تعریف یک ستون، نام یکی از مجموعه حرفهای پشتیبانی شده را پس از تعریف نوع ستون بنویسید، مانند:
![]()
در MySQL میتوانید مجموعه حرف پیشفرض را برای کل پایگاه داده خود نیز تنظیم کنید:
![]()
اگرچه مطالبی که در مورد مجموعه حروف ذکر شد، به اندازه کافی برای یک کتاب مقدماتی مناسب است، اما در مورد بینالمللیسازی یک پایگاهداده، نسبت به آنچه در اینجا نشان داده شد، مطالب بسیار بیشتری وجود دارد.
اگر نیاز به ذخیره دادههایی دارید که ممکن است از محدودیت ۶۴ کیلوبایت برای ستونهای varchar فراتر رود، باید از یکی از انواع متن استفاده کنید.
|
گونه متنی |
حداکثر تعداد بایت |
|
tinytext |
255 |
|
text |
65,535 |
|
mediumtext |
16,777,215 |
|
longtext |
4,294,967,295 |
جدول 1-2. دادههای متنی MySQL
هنگام انتخاب یکی از گونههای متن، باید از موارد زیر آگاه باشید:
· اگر دادههایی که در یک ستون متنی وارد میشوند از حداکثر اندازه برای آن نوع بیشتر شوند، دادهها کوتاه میشوند.
· هنگام ورود دادهها در ستون، فاصلههای انتهایی حذف نمیشوند.
· هنگام استفاده از ستونهای text برای مرتبسازی یا گروهبندی، فقط از ۱۰۲۴ بایت اول استفاده میشود، اگرچه در صورت لزوم میتوان این محدودیت را افزایش داد.
· گونههای مختلف متنی مختص MySQL هستند. SQL Server یک گونه text برای دادههای حرفی بزرگ دارد، در حالی که DB2 و Oracle از یک نوع گونه به نام clob برای اشیاء حرفی بزرگ استفاده میکنند.
· حالا که MySQL حداکثر 65535 بایت را برای ستونهای varchar را مجاز میداند (در نسخه 4 به 255 بایت محدود شده بود)، دیگر نیازی به استفاده از نوع tinytext یا text نیست .
اگر در حال ایجاد ستونی برای ورود دادههای بدون-فرم هستید، مثلاً ستون یادداشتها برای نگهداری دادههای مربوط به تعاملات مشتری با بخش خدمات مشتریان، احتمالاً گونه varchar برای اینکار کافی خواهد بود. با این حال، اگر در حال ذخیره اسناد هستید، باید نوع داده mediumtext یا longtext را انتخاب کنید.

اگرچه ممکن است معقول به نظر برسد که یک نوع داده عددی واحد به نام «numeric» داشته باشیم ، اما همانطور که در زیر نشان داده شده، در واقع چندین نوع داده عددی مختلف وجود دارد که روشهای مختلف استفاده از اعداد را نشان میدهد:
|
برای ستونی که نشان دهنده این است که آیا سفارش مشتری ارسال شده یا نه |
این نوع ستون، که به عنوان یک ستون بولی (Boolean) شناخته میشود، شامل عدد0 برای نشان دادن نادرست (false) و یک عدد 1 برای نشان دادن درست (true) خواهد بود. |
|
برای ستونی که کلید اصلی تولید شده توسط سیستم برای جدول تراکنشها را نشان میدهد
|
این دادهها عموماً از عدد ۱ شروع میشوند و با افزایش یک واحدی تا رسیدن به اعداد بسیار بزرگ افزایش مییابند. |
|
برای ستونی که شماره یک کالا برای سبد خرید الکترونیکی مشتری را نشان میدهد |
مقادیر این نوع ستون، اعداد صحیح مثبت بین ۱ و شاید ۲۰۰ (برای افراد معتاد به خرید) خواهد بود. |
|
دادههای مکانی برای دستگاه سوراخکن برد مدار چاپی |
دادههای علمی یا تولیدی با دقت بالا اغلب نیاز به دقتی تا هشت رقم اعشار دارند. |
برای مدیریت این نوع دادهها (و موارد دیگر)، MySQL چندین گونه داده عددی مختلف دارد. رایجترین گونههای عددی، آنهایی هستند که برای ذخیره اعداد صحیح از آنها استفاده میشوند. هنگام مشخص کردن یکی از این گونهها، میتوانید مشخص کنید که دادهها بدون علامت باشند (unsigned)، که به سرور میگوید تمام دادههای ذخیره شده در ستون بزرگتر یا مساوی صفر خواهند بود. جدول 2-2 پنج نوع داده مختلف مورد استفاده برای ذخیره اعداد صحیح را نشان میدهد.
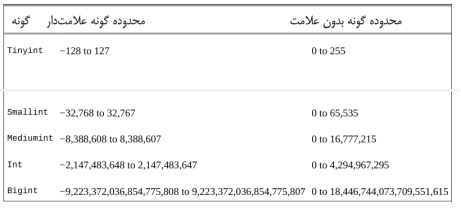
جدول 2-2. گونههای صحیح در MySQL
وقتی ستونی را با استفاده از یکی از گونههای عددی صحیح ایجاد میکنید، MySQL مقدار مناسبی از فضا را برای ذخیره دادهها اختصاص میدهد که از یک بایت برای tinyint، تا هشت بایت برای bigint متغیر است. بنابراین، باید سعی کنید گونهای را انتخاب کنید که به اندازه کافی بزرگ باشد تا بزرگترین عددی را که میخواهید در ستون ذخیره کنید، بدون هدر دادن بیمورد فضا، در خود جای دهد.
برای اعداد اعشاری (مانند ۳.۱۴۱۵۹۲۷)، میتوانید از انواع عددی نشان داده شده در جدول 3-2 استفاده کنید.
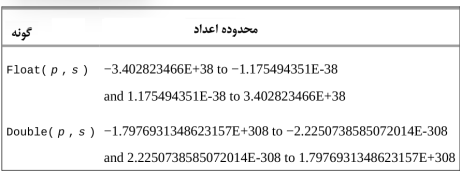
جدول 3-2. گونههای اعشاری MySQL
هنگام استفاده از گونههای اعشاری، میتوانید دقت (یعنی تعداد کل ارقام مجاز در سمت چپ و راست نقطه اعشاری) و مقیاس (تعداد ارقام مجاز در سمت راست نقطه اعشاری) را مشخص کنید، اما اینکار الزامی نیستند. این مقادیر در جدول 3-2 به صورت p و s نشان داده شدهاند. اگر دقت و مقیاس را برای ستون اعشاری خود مشخص میکنید، توجه داشته باشید که اگر تعداد ارقام از مقیاس بیشتر شود، دادههای ذخیره شده در ستون گِرد میشوند. به عنوان مثال، ستونی که به صورت float(4,2) تعریف میشود، در مجموع چهار رقم، دو رقم در سمت چپ اعشار و دو رقم در سمت راست اعشار را ذخیره میکند. بنابراین، چنین ستونی اعداد 27.44 و 8.19 را به خوبی مدیریت میکند، اما عدد 17.8675 به 17.87 گرد میشود و تلاش برای ذخیره عدد 178.375 در ستونی که بصورت float(4,2) تعریف شد، خطا ایجاد میکند.
مانند گونههای عددی صحیح، گونههای اعشاری را میتوان به صورت بدونعلامت تعریف کرد، اما این نامگذاری فقط از ذخیره اعداد منفی در ستون جلوگیری میکند و محدوده دادههایی که میتوان در ستون ذخیره کرد را تغییر نمیدهد.
شما در کنار رشتهها و اعداد، مطمئناً با اطلاعاتی در مورد تاریخها و یا زمانها سر و کار خواهید داشت. این گونه از دادهها به عنوان دادههای زمانی (temporal) شناخته میشوند. برخی از نمونه دادههای زمانی در یک پایگاه داده عبارتند از:
· تاریخی که انتظار میرود یک رویداد خاص رخ دهد، مانند ارسال سفارش مشتری
· تاریخ ثبت سفارش مشتری
· تاریخ و زمانی که کاربر یک ردیف خاص را در یک جدول تغییر داده است
· تاریخ تولد یک کارمند
· سال مربوط به یک ردیف در جدول yearly_sales در یک انبار داده
· زمان سپری شده برای تکمیل ساخت سیمکشی در خط مونتاژ خودرو
برای مدیریت همه این موارد، MySQL گونههای مختلفی را در نظر گرفته است. جدول 4-2 انواع دادههای زمانی پشتیبانی شده توسط MySQL را نشان میدهد.
جدول 4-2. گونههای زمانی MySQL
سرورهای پایگاه داده دادههای زمانی را به روشهای مختلف ذخیره میکنند، ولی هدف از یک رشته قالببندی (ستون دوم جدول 4-2) نشان دادن نحوه نمایش دادهها هنگام بازیابی، و نحوه ساخت یک رشته تاریخ هنگام درج یا بهروزرسانی یک ستون زمانی است. بنابراین، اگر میخواستید تاریخ 23 مارس 2020 را با استفاده از قالب پیشفرض YYYY-MM-DD در یک ستون تاریخ وارد کنید، از رشته '2020-03-23' استفاده میکردید. فصل 7 به طور کامل نحوه ساخت و نمایش دادههای زمانی را بررسی میکند.
همچنین گونههای datetime، timestamp و time امکان نمایش کسرهایی از ثانیه تا 6 رقم اعشار (میکرو ثانیه) را فراهم میکنند. هنگام تعریف ستونها با استفاده از یکی از این گونهها، میتوانید مقداری از 0 تا 6 را وارد کنید؛ برای مثال، تعیین datetime(2) اجازه میدهد تا مقادیر زمانی شما شامل صدم ثانیه نیز باشند.

جدول 5-2 اجزاء مختلف قالبهای تاریخ نشان داده شده در جدول 4-2 را شرح میدهد.
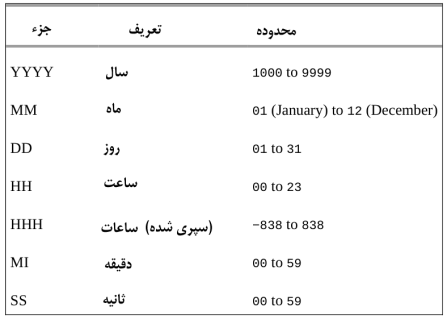
جدول 5-2. اجزای قالب تاریخ
در اینجا نحوه استفاده از گونههای زمانی مختلف برای پیادهسازی مثالهای قبلی آمده است :
· ستونهایی که تاریخ ارسال سفارش مشتری و تاریخ تولد کارمند را در خود نگه میدارند، از گونه date استفاده میکنند، زیرا برنامهریزی ارسال با دقت ثانیه غیرواقعی است و دانستن زمان دقیق تولد یک شخص نیز ضروری نیست.
· ستونی که اطلاعات مربوط به زمان ارسال سفارش مشتری را در خود نگه میدارد، باید از گونه datetime استفاده کند، زیرا نه تنها دانستن تاریخ ارسال مهم است، بلکه زمان آن نیز اهمیت دارد.
· ستونی که آخرین تغییر یک ردیف خاص در جدول توسط کاربر را ثبت میکند، از گونه timestamp استفاده میکند. گونه timestamp همان اطلاعات گونه datetime (سال، ماه، روز، ساعت، دقیقه، ثانیه) را در خود نگه میدارد، اما ستون timestamp به طور خودکار توسط سرور MySQL هنگام اضافه شدن یک ردیف به جدول یا تغییر بعدی یک ردیف، با تاریخ/زمان فعلی پر میشود.
· ستونی که فقط دادههای سال را در خود نگه میدارد، از گونه year استفاده میکند.
· ستونهایی که دادههای مربوط به مدت زمان لازم برای تکمیل یک کار را در خود نگه میدارند، از گونه time استفاده میکنند. برای این نوع دادهها، ذخیره جزئی از تاریخ غیرضروری و گیجکننده خواهد بود، زیرا شما فقط به تعداد ساعت/دقیقه/ثانیه مورد نیاز برای تکمیل کار علاقهمند هستید. این اطلاعات را میتوان با استفاده از دو ستون تاریخ/زمان (یکی برای تاریخ/زمان شروع کار و دیگری برای تاریخ/زمان تکمیل کار) و کم کردن یکی از دیگری به دست آورد، اما استفاده از یک ستون زمان سادهتر است.
فصل 7 نحوه کار با هر یک از این گونههای زمانی را بررسی میکند.
حالا که درک کاملی از انواع گونههایی که میتوان در پایگاه داده MySQL ذخیره کرد، دارید، وقت آن است که ببینیم چگونه از این گونهها در تعریف جدول استفاده کنیم. بیایید با تعریف یک جدول برای نگهداری اطلاعات مربوط به یک شخص شروع کنیم.
...........................................
محتویات کامل این کتاب در 18 فصل و 550 صفحه منتشر شده، برای ادامه مطالعه این کتاب میتوانید نسخه کامل PDF آن را تهیه کنید.
در دو فصل اول این کتاب چند نمونه از پرسوجوهای پایگاه داده (معروف به دستورات select) را دیدید. اکنون زمان آن رسیده است که نگاهی دقیقتر به بخشهای مختلف دستور select و نحوه تعامل آنها بیندازیم. پس از اتمام این فصل، شما باید درک اولیهای از نحوه بازیابی، اتصال، فیلتر کردن، گروهبندی و مرتبسازی دادهها داشته باشید. این مباحث به تفصیل در فصلهای ۴ تا ۱۰ پوشش داده خواهند شد.
قبل از بررسی دستور select، شاید جالب باشد که نگاهی به نحوه اجرای پرسوجوها توسط سرور MySQL (و فرقی نمیکند، تمام سرورهای پایگاه داده) بیندازیم. اگر از ابزار خط فرمان mysql استفاده میکنید (که من این طور فرض میکنم)، پس با ارائه نام کاربری و رمز عبور خود (و اگر سرور MySQL روی کامپیوتر دیگری در حال اجرا است، احتمالاً یک نام میزبان) به سرور MySQL وارد شدهاید. پس از تأیید نام کاربری و رمز عبور شما توسط سرور، یک اتصال پایگاه داده برای استفاده شما ایجاد میشود. این اتصال توسط برنامهای که آن را درخواست کرده است (که در این مورد، ابزار mysql است) نگه داشته میشود تا زمانی که برنامه اتصال را آزاد کند (یعنی quit را تایپ کنید) یا سرور اتصال را ببندد (یعنی وقتی سرور خاموش میشود). به هر اتصال به سرور MySQL یک شناسه اختصاص داده میشود که هنگام اولین ورود به سیستم به شما نشان داده میشود:
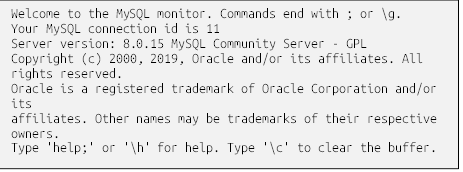
در این مورد، شناسه اتصال من ۱۱ است. این اطلاعات ممکن است برای مدیر پایگاه داده شما مفید باشد اگر مشکلی پیش بیاید، مثل یک پرسوجوی ناقص که ساعتها درحال اجرا است، شاید بخواهید آن را یادداشت کنید.
پس از اینکه نام کاربری و رمز عبور شما توسط سرور تأیید شد و اتصال برقرار گردید، شما آماده اجرای پرسوجوها (همراه با سایر دستورات SQL) هستید. هر بار که یک پرسوجو به سرور ارسال میشود، سرور قبل از اجرای دستور، موارد زیر را بررسی میکند:
· آیا شما اجازه اجرای دستور را دارید؟
· آیا شما اجازه دسترسی به دادههای مورد نظر را دارید؟
· آیا نحو (syntax) دستور شما صحیح است؟
اگر دستور شما این سه آزمون را با موفقیت پشت سر بگذارد، آنگاه پرسوجوی شما به بهینهساز پرسوجو تحویل داده میشود که وظیفه آن تعیین کارآمدترین روش برای اجرای پرسوجو است. بهینهساز به مواردی مانند ترتیب اتصالِ جداول نامگذاری شده در بندِ from و ایندکسهای موجود توجه میکند و سپس یک طرح اجرایی را انتخاب میکند که سرور برای اجرای پرسوجوی شما از آن استفاده میکند.

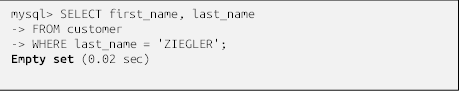
پس از اینکه سرور اجرای پرسوجو شما را به پایان رساند، مجموعه نتایج به برنامه فراخوانی کننده (که باز هم ابزار mysql است) بازگردانده میشود. همانطور که در فصل 1 اشاره کردم، مجموعه نتایج فقط عبارت است از جدولی که شامل ردیفها و ستونها است. اگر پرسوجو شما هیچ نتیجهای به همراه نداشته باشد، ابزار mysql پیامی را که در انتهای مثال زیر آمده است به شما نشان میدهد:
همانطور که در مثال بعدی نشان داده شده، اگر پرسوجو یک یا چند ردیف را برگرداند، ابزار mysql با اضافه کردن سرستونها و ایجاد کادرهایی در اطراف ستونها با استفاده از نمادهای -، | و +، نتایج را قالببندی میکند:
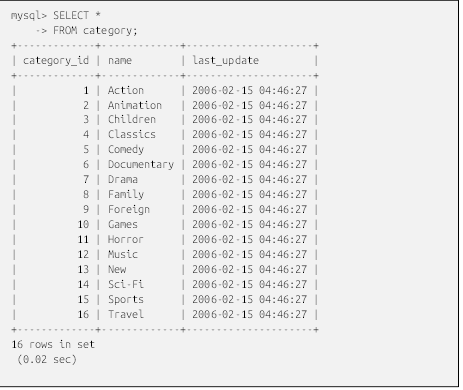
این پرسوجو هر سه ستونِ تمامِ ردیفهای جدول category را برمیگرداند. پس از نمایش آخرین ردیف دادهها، ابزار mysql پیامی را نمایش میدهد که به شما میگوید چند ردیف برگردانده شده است، که در این مورد، ۱۶ است.
دستور select دارای چند جزء یا بندِ (Clauses) است. در حالی که فقط یکی از آنها هنگام استفاده از MySQL اجباری است (بندِ select)، ولی معمولاً دستور شما حداقل شامل دو یا سه مورد از شش بندِ نیز هست. جدول 3-1 بندهای مختلف و اهداف آنها را نشان میدهد.
|
نام جزء |
وظیفه |
|
select |
تعیین میکند که کدام ستونها در مجموعه نتایج پرسوجو لحاظ شوند. |
|
from |
جداولی که دادهها باید از آنها بازیابی شود و نحوه اتصال جداول را مشخص میکند. |
|
where |
دادههای ناخواسته را فیلتر میکند. |
|
group by |
برای گروه بندی ردیفها بر اساس مقادیر ستون مشترک استفاده می شود. |
|
having |
گروههای ناخواسته را فیلتر میکند. |
|
order by |
ردیفهای نتیجه نهایی را بر اساس یک یا چند ستون مرتب میکند. |
جدول1-3. بندهای مختلف یک پرسوجو
...........................................
محتویات کامل این کتاب در 18 فصل و 550 صفحه منتشر شده، برای ادامه مطالعه این کتاب میتوانید نسخه کامل PDF آن را تهیه کنید.
گاهی اوقات شما میخواهید با تمام ردیفهای یک جدول کار کنید، مثلاً:
· حذف تمام دادهها از جدولی که برای آمادهسازی ورودیهای جدید انبار داده استفاده میشود
· تغییر تمام ردیفهای یک جدول پس از اضافه شدن یک ستون جدید
· بازیابی تمام ردیفها از جدولِ صفِ پیامها
در مواردی از این دست، دستوراتِ SQL نیازی به داشتن عبارت where نخواهند داشت، زیرا نیازی به فیلتر کردن هیچ ردیفی ندارید . ولی اغلب اوقات شما میخواهید تمرکز خود را به زیرمجموعهای از ردیفهای یک جدول محدود کنید. بنابراین، تمام دستورات داده SQL (به جز دستور insert) شامل یک عبارت where اختیاری هستند که شامل یک یا چند شرط فیلتر است که برای محدود کردن تعداد ردیفهایی که دستور SQL روی آنها عمل میکند، استفاده میشود. علاوه بر این، دستور select شامل یک عبارت having است که در آن میتوان شرطهای فیلتر مربوط به دادههای گروهبندی شده را گنجاند. این فصل انواع مختلف شرطهای فیلتر کردن را که میتوانید در بندِ where برای دستورات select، update و delete به کار ببرید، را بررسی میکند. در فصل 8 استفاده از شرطهای فیلتر را در عبارت having مربوط به دستور select نشان میدهم.
یک عبارت where میتواند شامل یک یا چند شرط باشد که توسط عملگرهای and و or از هم جدا شدهاند. اگر چندین شرط فقط توسط عملگر and از هم جدا شده باشند، برای اینکه ردیف در مجموعه نتایج قرار گیرد، باید تمام شرطها درست ارزیابی شوند. عبارت where زیر را در نظر بگیرید:

با توجه به این دو شرط، فقط ردیفهایی که نام آنها STEVEN، و تاریخ ایجاد آنها بعد از ۱ ژانویه ۲۰۰۶ باشد، در مجموعه نتایج قرار خواهند گرفت. اگرچه این مثال فقط از دو شرط استفاده میکند، ولی مهم نیست چند شرط در عبارت where وجود داشته باشد، اگر آنها توسط عملگر and از هم جدا شده باشند، برای اینکه ردیف در مجموعه نتایج قرار گیرد، باید همه آنها درست برآورد شوند.
اگر تمام شرطهای موجود در عبارت where توسط عملگر or از هم جدا شده باشند، فقط یکی از شرطها باید درست باشد تا ردیف در مجموعه نتایج قرار گیرد. دو شرط زیر را در نظر بگیرید:
![]()
اکنون روشهای مختلفی برای قرار دادن یک ردیف مشخص در مجموعه نتایج وجود دارد:
· نام کوچک 'STEVEN' است و تاریخ ایجاد آن بعد از ۱ ژانویه ۲۰۰۶ بوده است.
· نام کوچک 'STEVEN' است و تاریخ ایجاد آن اول ژانویه ۲۰۰۶ یا قبل از آن بوده است.
· نام کوچک هر چیزی غیر از 'STEVEN' است، اما تاریخ ایجاد آن بعد از ۱ ژانویه ۲۰۰۶ بوده است.
جدول 1-4 نتایج ممکن برای یک عبارت where شامل دو شرط که توسط عملگر or از هم جدا شدهاند را نشان میدهد.
|
نتیجه میانی |
نتیجه نهایی |
|
WHERE true OR true |
True |
|
WHERE true OR false |
True |
|
WHERE false OR true |
True |
|
WHERE false OR false |
False |
جدول 1-4. ارزیابی دو شرط
در مثال قبل، تنها راه برای حذف یک ردیف از مجموعه نتایج این است که نام کوچک شخص Steven نباشد و تاریخ ایجاد آن ۱ ژانویه ۲۰۰۶ یا قبل از آن باشد.
شما میتوانید با استفاده از حروف عام (wildcard) نشان داده شده در جدول 4-4، برای شناسایی این موارد و بسیاری از تطابقهای جزئی رشتهای دیگر، عبارات جستجو بسازید.
...........................................
محتویات کامل این کتاب در 18 فصل و 550 صفحه منتشر شده، برای ادامه مطالعه این کتاب میتوانید نسخه کامل PDF آن را تهیه کنید.
در فصل 1 نشان داده شد که چگونه مفاهیم مرتبط از طریق فرآیندی به نام نرمالسازی به قطعات جداگانه تقسیم میشوند. نتیجه نهایی این تمرین دو جدول بود: person و favorite_food. با این حال، اگر میخواهید یک گزارش واحد ایجاد کنید که نام، آدرس، و غذاهای مورد علاقه یک شخص را نشان دهد، به مکانیزمی نیاز خواهید داشت تا دادههای این دو جدول را دوباره کنار هم قرار دهد. این مکانیزم به عنوان اتصال جداول یا join شناخته میشود. این فصل بر سادهترین و رایجترین اتصالها، یعنی inner join، تمرکز دارد. فصل ۱۰ انواع مختلف join را نشان میدهد.
پرسوجوهایی که از فقط یک جدول استفاده میکنند، قطعاً کم نیستند، اما متوجه خواهید شد که اکثر پرسوجوهای شما به دو، سه، یا حتی تعداد بیشتری جدول نیاز دارند. برای روشن شدن موضوع، بیایید نگاهی به تعاریف جداول مشتری و آدرس بیندازیم و سپس پرسوجویی تعریف کنیم که دادهها را از هر دو جدول بازیابی کند:

فرض کنید میخواهید نام و نام خانوادگی هر مشتری را به همراه آدرس خیابان آنها بازیابی کنید. بنابراین، پرسوجو شما باید ستونهای customer.first_name، customer.last_name و address.address را بازیابی کند. اما چگونه میتوانید دادهها را از هر دو جدول در یک پرسوجو بازیابی کنید؟ پاسخ در ستون customer.address_id نهفته است که مشخص کننده شناسه مشتری در جدول address است ( به عبارت رسمیتر، ستون customer.address_id کلید خارجی جدول address است). پرسوجوی که به زودی آن را خواهید دید، به سرور دستور میدهد تا از ستون customer.address_id به عنوان وسیله پیوند بین جداول مشتری و آدرس استفاده کند و درنتیجه به ستونهای هر دو جدول اجازه میدهد تا در مجموعه نتایج پرسوجو گنجانده شوند . این نوع عملیات به عنوان اتصال جداول یا join شناخته میشود.

سادهترین راه برای شروع اتصال دو جدولcustomer و address، قرار دادن نام آنها در عبارت from یک پرسوجو و مشاهدهی نتیجه است. در اینجا پرسوجویی را مشاهده میکنید که نام و نام خانوادگی مشتری را به همراه آدرس خیابان او بازیابی میکند، و هر دو جدول با استفاده از بندِ from و با استفاده از کلمه کلیدی join از هم جدا شدهاند:
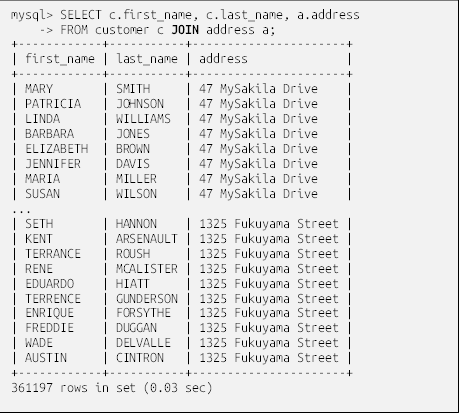
عجیب است! ما فقط ۵۹۹ مشتری و ۶۰۳ ردیف در جدول آدرس داریم، پس چطور مجموعه نتایج به ۳۶۱,۱۹۷ ردیف رسیده است؟ با نگاهی دقیقتر، میتوانید ببینید که به نظر میرسد آدرس خیابان بسیاری از مشتریان یکسان است. از آنجا که پرسوجو نحوه اتصال دو جدول را مشخص نکرده است، سرور پایگاه داده حاصلضرب دکارتی (Cartesian product) دو جدول را به ما داده ، که برابر با تمام جایگشتهای دو جدول (۵۹۹ مشتری × ۶۰۳ آدرس = ۳۶۱,۱۹۷ جایگشت). این نوع اتصال به عنوان اتصال متقاطع (cross join) نیز شناخته میشود و به ندرت از آن استفاده میشود. اتصالهای متقاطع یکی از انواع اتصالهایی هستند که در فصل ۱۰ مطالعه میکنیم.
برای اصلاح پرسوجو قبلی، طوری که فقط یک ردیف برای هر مشتری برگردانده شود، باید نحوه ارتباط دو جدول را مشخص کنیم. قبلاً نشان دادم که ستون customer.address_id به عنوان عامل پیوند بین دو جدول عمل میکند، بنابراین این اطلاعات باید به زیربندِ on بندِ from اضافه شود:
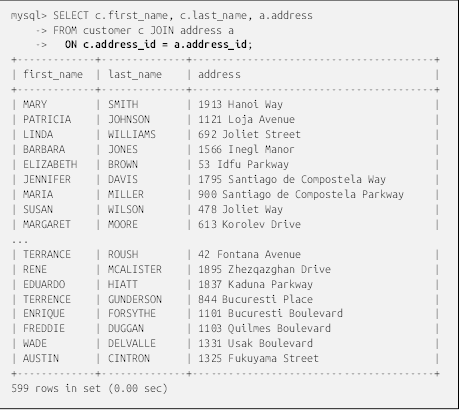
حالا به دلیل اضافه شدن زیربندِ on، تعداد ردیفهای مورد انتظار به جای ۳۶۱,۱۹۷ ردیف ۵۹۹ است که به سرور دستور میدهد با استفاده از ستون address_id برای پیمایش یک جدول به جدول دیگر، جداول مشتری و آدرس را به هم متصل کند. به عنوان مثال، ردیف Mary Smith در جدول مشتری حاوی مقدار ۵ در ستون address_id است (که در مثال نشان داده نشده است). سرور از این مقدار برای جستجوی ردیفی در جدول آدرس که مقدار ۵ در ستون address_id آن است استفاده میکند و سپس مقدار '۱۹۱۳ Hanoi Way' را از ستون آدرس در آن ردیف بازیابی میکند.
اگر مقداری برای ستون address_id در یک جدول وجود داشته باشد اما برای جدول دیگر وجود نداشته باشد، عمل اتصال برای ردیفهای حاوی آن مقدار با شکست مواجه میشود و آن ردیفها از مجموعه نتایج حذف میشوند. این نوع اتصال به عنوان اتصال درونی (inner join) شناخته میشود و رایجترین نوع پیوند مورد استفاده است. برای روشن شدن موضوع، مثلاً اگر ردیفی در جدول مشتری در ستون address_id مقدار 999 داشته باشد و هیچ ردیفی در جدول آدرس با مقدار 999 در ستون address_id وجود نداشته باشد، آن ردیف در مجموعه نتایج گنجانده نخواهد شد. اگر صرف نظر از وجود تطابق، میخواهید تمام ردیفهای یک جدول یا جدول دیگر را وارد کنید، باید یک اتصال خارجی مشخص کنید، اما این موضوع در فصل 10 بررسی خواهد شد.
در مثال قبل من در بندِ from نوع join مورد استفاده را مشخص نکردم. ولی وقتی میخواهید دو جدول را با استفاده از inner join به هم متصل کنید، باید این مورد را به صراحت در بندِ from خود مشخص کنید؛ در اینجا همان مثال را میبینید، با این تفاوت که نوع join را نیز اضافه کردهایم (به کلمه کلیدی inner توجه کنید):

...........................................
محتویات کامل این کتاب در 18 فصل و 550 صفحه منتشر شده، برای ادامه مطالعه این کتاب میتوانید نسخه کامل PDF آن را تهیه کنید.
اگرچه میتوانید هر بار با دادههای یک پایگاه داده، به صورت سطری تعامل داشته باشید، اما در واقع پایگاههای داده رابطهای در مورد مجموعهها هستند. این فصل به بررسی نحوه ترکیب چندین مجموعه از نتایج با استفاده از عملگرهای مختلف مجموعه میپردازد. پس از مروری سریع بر نظریه مجموعهها، نحوه استفاده از عملگرهای مجموعه، مانند union، intersect و except برای ترکیب چندین مجموعه داده با یکدیگر را نشان خواهم داد.
در بسیاری از نقاط جهان، نظریه پایه مجموعهها در برنامههای درسی ریاضی سطح ابتدایی گنجانده شده است. شاید به یاد داشته باشید که به چیزی شبیه به آنچه در شکل 1-6 نشان داده شده است، نگاه کردید.
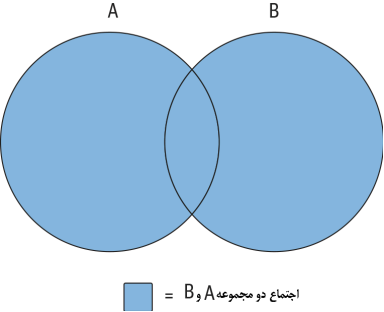
شکل1-6. عمل اجتماع (اتحاد) دو مجموعه A و B
ناحیه سایهدار در شکل 1-6 نشان دهنده اجتماع (یا اتحاد) مجموعههای A و B است که ترکیبی از هر دو مجموعه است (و تمام نواحی همپوشانی شده فقط یک بار در آن لحاظ شده است). آیا این آشنا به نظر میرسد؟ اگر چنین است، پس بالاخره فرصتی برای استفاده از این دانش خواهید داشت؛ اگر نه، نگران نباشید، زیرا تجسم آن با استفاده از چند نمودار آسان است.
با استفاده از دایرهها برای نمایش دو مجموعه داده (A و B)، زیرمجموعهای از دادهها را تصور کنید که در هر دو مجموعه مشترک است؛ این دادههای مشترک با ناحیه همپوشانی نشان داده شده در شکل 6-1 نمایش داده شده است. از آنجایی که نظریه مجموعهها بدون همپوشانی بین مجموعه دادهها چندان جالب نیست، من از همان نمودار برای نشان دادن تمام عملیات مجموعهها استفاده میکنم. عملیات دیگری برای مجموعهها وجود دارد که فقط به همپوشانی بین دو مجموعه داده مربوط میشود. این عملیات به عنوان تقاطع (یا اشتراک) شناخته میشود و در شکل 2-6 نشان داده شده است.
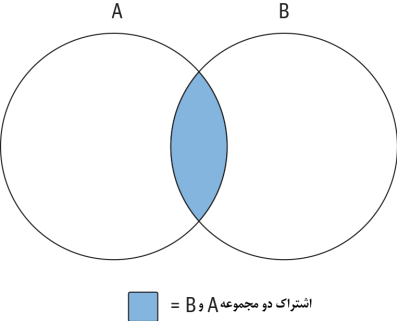
شکل 2-6. عمل تقاطع (اشتراک) دو مجموعه A و B
مجموعه دادهای که از تقاطع مجموعههای A و B ایجاد میشود، دقیقاً همان ناحیه همپوشانی بین دو مجموعه است. اگر دو مجموعه هیچ همپوشانی نداشته باشند، آنگاه نتیجه عمل اشتراک، یک مجموعه تهی خواهد بود.
سومین و آخرین عمل مجموعه، که در شکل3-6 نشان داده شده است، به عنوان عمل تفریق شناخته میشود.
شکل 3-6 نتیجه (A except B) یا (A-B) را نشان میدهد، که برابر است با کل مجموعه A منهای هرگونه همپوشانی با مجموعه B. اگر دو مجموعه هیچ همپوشانی نداشته باشند، آنگاه نتیجه عمل تفریق A و B، کل مجموعه A خواهد بود.
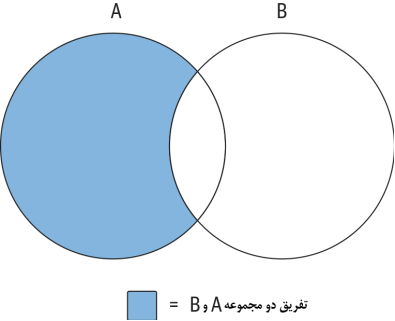
شکل 3-6. عمل تفریق دو مجموعه A و B
با استفاده از این سه عملیات، یا با ترکیب عملیات مختلف با یکدیگر، میتوانید هر نتیجهای را که نیاز دارید، تولید کنید. برای مثال، تصور کنید که میخواهید مجموعهای مطابق شکل 4-6 بسازید.
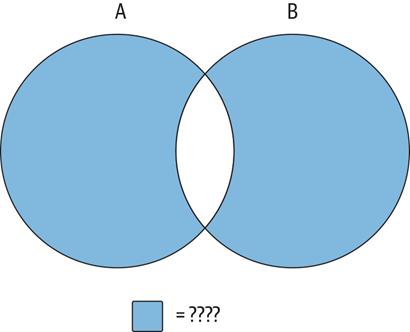
شکل 4-6. مجموعه دادههای مرموز
مجموعه دادهای که به دنبال آن هستید شامل کُل مجموعههای A و B بدون ناحیه همپوشانی است. شما نمیتوانید تنها با یکی از سه عملیاتی که قبلاً نشان داده شده است به این نتیجه برسید. در عوض، ابتدا باید یک مجموعه داده بسازید که کُل مجموعههای A و B را در بر بگیرد، و سپس از یک عمل دیگری برای حذف ناحیه همپوشانی استفاده کنید. اگر مجموعه کُل به صورت A union B و ناحیه همپوشانی به صورت A intersect B توصیف شود، آنگاه عملیاتی که برای تولید مجموعه داده نشان داده شده در شکل 6-4 مورد نیاز است به شرح زیر خواهد بود:
![]()
البته، قالباً روشهای متعددی برای دستیابی به نتایج یکسان وجود دارد؛ شما میتوانید با استفاده از عملیات زیر به نتیجه مشابهی برسید:
![]()
اگرچه درک این مفاهیم با استفاده از نمودارها نسبتاً آسان است، بخشهای بعدی به شما نشان میدهند که چگونه این مفاهیم با استفاده از عملگرهای مجموعهای SQL در یک پایگاه داده رابطهای اعمال میشوند.
دایرههایی که در نمودارهای بخش قبلی برای نمایش مجموعه دادهها استفاده شدند، چیزی در مورد اینکه مجموعه دادهها شامل چه چیزهایی هستند، بیان نمیکردند. با این حال، هنگام برخورد با دادههای واقعی، در صورت ترکیب مجموعه دادههای مربوطه، نیاز به توصیف ترکیب آنها وجود دارد. برای مثال، تصور کنید اگر سعی کنید اجتماع جدول مشتری و جدول شهر را ایجاد کنید، چه اتفاقی میافتد، که تعاریف آنها به شرح زیر است:
...........................................
محتویات کامل این کتاب در 18 فصل و 550 صفحه منتشر شده، برای ادامه مطالعه این کتاب میتوانید نسخه کامل PDF آن را تهیه کنید.
همانطور که در پیشگفتار اشاره کردم، این کتاب تلاش میکند تکنیکهای عمومی SQL را که میتوانند در اکثر سرورهای پایگاه داده اعمال شوند، آموزش دهد. با این حال، این فصل به تولید، تبدیل و دستکاری دادههای رشتهای، عددی و زمانی میپردازد. ولی زبان SQL شامل دستوراتی نیست که این قابلیت را پوشش دهند. در عوض، از توابع داخلی برای تسهیل تولید، تبدیل و دستکاری دادهها استفاده میشود و هرچند استاندارد SQL برخی از توابع را مشخص میکند، تولیدکنندگان پایگاه داده اغلب با مشخصات این توابع مطابقت ندارند.
بنابراین، رویکرد من در این فصل این است که برخی از روشهای رایج تولید و دستکاری دادهها در دستورات SQL را به شما نشان دهم و سپس برخی از توابع داخلی پیادهسازی شده توسط Microsoft SQL Server، Oracle Database و MySQL را شرح دهم. در کنار خواندن این فصل، اکیداً توصیه میکنم یک راهنمای مرجع که تمام توابع پیادهسازی شده توسط سرور شما را پوشش میدهد، دانلود کنید.
هنگام کار با دادههای رشتهای، از یکی از انواع دادههای حرفی زیر استفاده خواهید کرد:
رشتههای با طول ثابت و فضای خالی را نگه میدارد. MySQL اجازه میدهد مقادیر CHAR طولی تا ۲۵۵ حرف داشته باشند، پایگاه داده Oracle تا ۲۰۰۰ حرف، و SQL Server تا ۸۰۰۰ حرف را اجازه میدهند.
یک ستون از گونه varchar رشتههایی با طول متغیر را در خود جای میدهد. MySQL تا ۶۵۵۳۵ حرف، Oracle Database (از طریق گونه varchar2) تا ۴۰۰۰ حرف، و SQL Server تا ۸۰۰۰ حرف را مجاز میدانند.
این ستونها رشتههای متنی با طولِ متغیرِ بسیار بزرگ (که عموماً در این زمینه به عنوان سند شناخته میشوند) را در خود نگه میدارد. MySQL گونههای متنی متعددی برای اسنادی تا حجم ۴ گیگابایت دارد (tinytext، text، mediumtext و longtext). SQL Server یک گونه متنی برای اسنادی تا حجم ۲ گیگابایت دارد و Oracle Database گونه clob را شامل میشود که میتواند اسنادی تا حجم عظیم ۱۲۸ ترابایت را در خود نگه دارد. همچنین SQL Server 2005 گونه varchar(max) را شامل میشود و استفاده از آن را به جای گونه text توصیه میکند، که در نسخههای بعدی از این سرور حذف خواهد شد.
برای نشان دادن نحوه استفاده از این گونههای مختلف، برای برخی از مثالهای این بخش از جدول زیر استفاده میکنم:

دو بخش بعدی نشان میدهد که چگونه میتوانید دادههای رشتهای را تولید کرده و آنها را تغییر دهید.
سادهترین راه برای پر کردن یک ستون حرفی، قرار دادن یک رشته در داخل علامت نقل قول است، مانند مثالهای زیر:
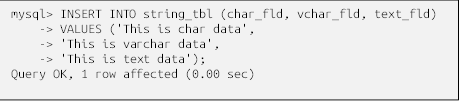
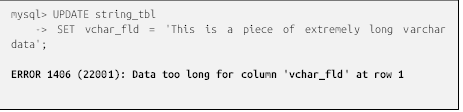
هنگام وارد کردن دادههای رشتهای در یک جدول، به یاد داشته باشید که اگر طول رشته از حداکثر اندازه برای ستونِ حرف (چه حداکثر تعیینشده و چه حداکثر مجاز برای نوع داده) بیشتر شود، سرور یک اعتراض (exception) را ایجاد میکند. اگرچه این رفتار پیشفرض برای تمام سرورها است، میتوانید MySQL و SQL Server را طوری پیکربندی کنید که به جای ایجاد اعتراض، بی سر و صدا رشته را کوتاه کنند. برای نشان دادن نحوه مدیریت این وضعیت توسط MySQL، دستور UPDATE زیر تلاش میکند تا ستون vchar_fld را که حداکثر طول آن 30 تعریف شده است، با رشتهای به طول 46 حرف تغییر دهد:
...........................................
محتویات کامل این کتاب در 18 فصل و 550 صفحه منتشر شده، برای ادامه مطالعه این کتاب میتوانید نسخه کامل PDF آن را تهیه کنید.
به طور کلی دادهها در پایینترین سطح جزئیات مورد نیاز هر یک از کاربران پایگاه داده ذخیره میشوند ؛ اگر شخصی نیاز به بررسی تراکنشهای تک تک مشتریان داشته باشد، باید در پایگاه داده جدولی وجود داشته باشد که تراکنشهای تک تک مشتریان را ذخیره کند. با این حال، این بدان معنا نیست که همه کاربران باید با دادهها به همان شکلی که در پایگاه داده ذخیره شدهاند، برخورد کنند. تمرکز این فصل بر چگونگی گروهبندی و تجمیع دادهها است تا کاربران نسبت به آنچه در پایگاه داده ذخیره شده است، بتوانند در سطح بالاتری از جزئیات با آنها تعامل داشته باشند.
گاهی اوقات میخواهید روندهایی را در دادههای خود پیدا کنید که سرور نیاز دارد قبل از اینکه بتوانید نتایج مورد نظر خود را تولید کنید، دادهها را کمی تغییر دهد. برای مثال، فرض کنید شما مسئول ارسال کوپن برای اجاره رایگان به مشتریان برتر خود هستید. میتوانید یک پرسوجوی ساده برای مشاهده دادههای خام ارسال کنید:
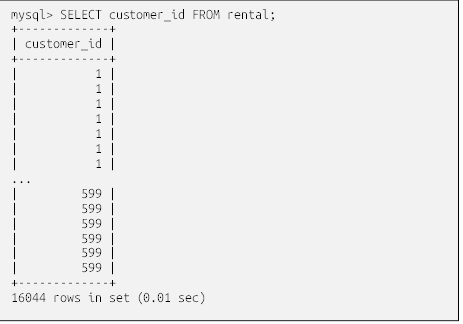
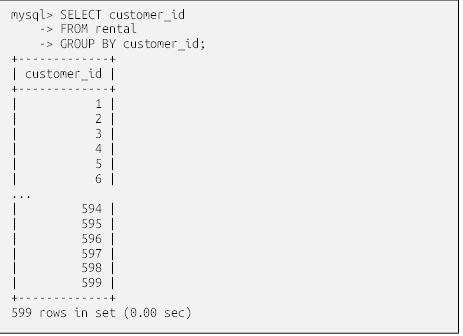
با وجود ۵۹۹ مشتری که بیش از ۱۶۰۰۰ رکورد اجاره را در بر میگیرند، با نگاه کردن به دادههای خام، تعیین اینکه کدام مشتریان بیشترین فیلم را اجاره کردهاند، امکانپذیر نیست. در عوض، میتوانید از سرور پایگاه داده بخواهید که دادهها را با استفاده از بندِ group by، برای شما گروهبندی کند. در اینجا همان پرسوجو را داریم ، اما برای گروهبندی دادههای اجاره بر اساس شناسه مشتری از بندِ group by استفاده میکنیم:
برای هر مقدار متمایز در ستون customer_id، مجموعه نتایج شامل یک ردیف است که به جای ۱۶۰۴۴ ردیف کامل، منجر به ۵۹۹ ردیف میشود. دلیل کوچکتر بودن مجموعه نتایج این است که برخی از مشتریان بیش از یک فیلم اجاره کردهاند. برای دیدن اینکه هر مشتری چند فیلم اجاره کرده است، میتوانید برای شمارش تعداد ردیفها در هر گروه، در عبارت select از تابع تجمیعی count استفاده کنید:
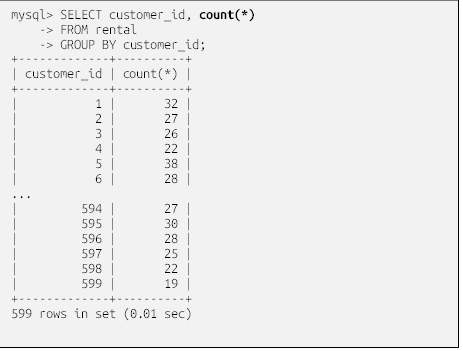
تابع تجمیعی count() تعداد ردیفهای هر گروه را میشمارد و علامت ستاره به سرور میگوید که همه چیز را در گروه بشمارد. با استفاده از ترکیب عبارت group by و تابع تجمیعی count()، میتوانید دقیقاً دادههای مورد نیاز برای پاسخ به سوال تجاری را بدون نیاز به نگاه کردن به دادههای خام تولید کنید.
با نگاهی به نتایج، میتوانید ببینید که ۳۲ فیلم توسط مشتری با شناسه ۱، و ۲۵ فیلم توسط مشتری با شناسه ۵۹۷ اجاره شده است. برای تعیین اینکه کدام مشتریان بیشترین فیلم را اجاره کردهاند، کافیست یک ترتیب بر اساس بندِ اضافه کنید:
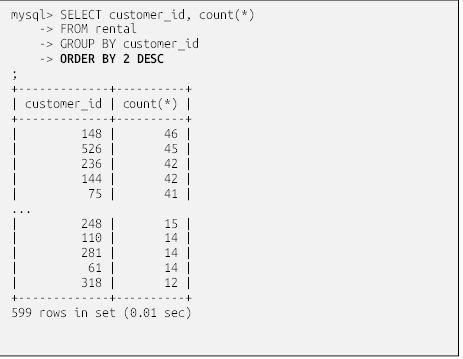
حالا که نتایج مرتب شدهاند، میتوانید به راحتی ببینید که مشتری با شناسه ۱۴۸ بیشترین تعداد فیلم را اجاره کرده است (۴۶)، در حالی که مشتری با شناسه ۳۱۸ کمترین تعداد فیلم را اجاره کرده است (۱۲).
هنگام گروهبندی دادهها، ممکن است لازم باشد دادههای نامطلوب را از مجموعه نتایج خود بر اساس گروههای دادهها فیلتر کنید، نه بر اساس دادههای خام. از آنجایی که عبارت group by پس از ارزیابی عبارت where اجرا میشود، برای این منظور نمیتوانید شرایط فیلتر را به عبارت where خود اضافه کنید. برای مثال، در اینجا تلاشی برای فیلتر کردن مشتریانی که کمتر از ۴۰ فیلم اجاره کردهاند، آمده است:
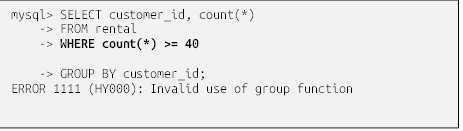
شما نمیتوانید در عبارت where تابع تجمعی count(*) را بیاورید، زیرا در زمان ارزیابی عبارت where گروهها هنوز تولید نشدهاند. در عوض، باید شرایط فیلتر گروه خود را در عبارت having قرار دهید. در اینجا نحوهی نمایش پرسوجو با استفاده از having آمده است:
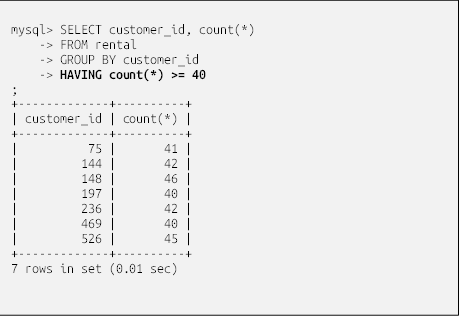
از آنجا که گروههایی که کمتر از ۴۰ عضو دارند از طریق عبارت having فیلتر شدهاند، اکنون مجموعه نتایج فقط شامل مشتریانی است که ۴۰ فیلم یا بیشتر اجاره کردهاند.
توابع تجمیع (Aggregate Functions)، عملیات خاصی را روی تمام ردیفهای یک گروه انجام میدهند. اگرچه تمام سرورهای پایگاه داده توابع تجمیع خاصِ خود را دارد، ولی توابع تجمیع رایج که در همه سرورهای عمده پیادهسازی شدهاند عبارتند از:
· max()
حداکثر مقدار را در یک مجموعه برمیگرداند
· min()
حداقل مقدار را در یک مجموعه برمیگرداند
· avg()
مقدار میانگین را در یک مجموعه برمیگرداند
· sum()
مجموع مقادیر یک مجموعه را برمیگرداند
· count()
تعداد مقادیر موجود در یک مجموعه را برمیگرداند
...........................................
محتویات کامل این کتاب در 18 فصل و 550 صفحه منتشر شده، برای ادامه مطالعه این کتاب میتوانید نسخه کامل PDF آن را تهیه کنید.
زیرپرسوجوها (Subqueries) ابزار قدرتمندی هستند که میتوانید از آنها در هر چهار دستور داده SQL استفاده کنید. در این فصل، به شما نشان خواهم داد که چگونه میتوان از زیرپرسوجوها برای فیلتر کردن دادهها، تولید مقادیر، و ساخت مجموعه دادههای موقت استفاده کنید. پس از کمی آزمایش، فکر میکنم شما هم موافق باشید که زیرپرسوجوها یکی از قدرتمندترین ویژگیهای زبان SQL هستند.
یک زیرپرسوجو، پرسوجویی است که درون یک دستور SQL دیگر قرار دارد (که در ادامه این بحث به آن عبارتِ دربردارنده (containing statement) میگویم). یک زیرپرسوجو همیشه درون پرانتز قرار میگیرد و معمولاً قبل از عبارتِ دربردارنده اجرا میشود. مانند هر پرسوجویی، یک زیرپرسوجو نیز مجموعهای از نتایج را برمیگرداند که ممکن است شامل موارد زیر باشد:
· یک ردیف با یک ستون
· چندین ردیف با یک ستون
· چندین ردیف با چندین ستون
نوع مجموعه نتایجی که توسط زیرپرسوجو برگردانده میشود، نحوه استفاده از آن و عملگرهایی را که عبارتِ دربردارنده آن میتواند برای تعامل با دادههایی که زیرپرسوجو برمیگرداند، استفاده کند، تعیین میکند. هنگامی که اجرای دستور دربردارنده به پایان رسید، دادههای برگردانده شده توسط هر زیرپرسوجو حذف میشوند و زیرپرسوجو مانند یک جدول موقت با دامنه دستور عمل میکند (به این معنی که سرور پس از پایان اجرای دستور SQL، هر حافظهای که به نتایج زیرپرسوجو اختصاص داده شده است را آزاد میکند).
شما در فصل های قبلی چندین مثال از زیرپرسوجوها را دیدهاید، اما در اینجا یک مثال ساده برای شروع کار آورده شده است:
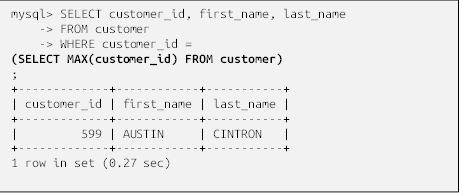
در این مثال، زیرپرسوجو حداکثر مقدار موجود در ستون customer_id در جدول مشتری را برمیگرداند، و سپس عبارت دربردارنده آن، دادههایی درباره آن مشتری را برمیگرداند. اگر در مورد عملکرد یک زیرپرسوجو سردرگم شدید، میتوانید زیرپرسوجو را به تنهایی (بدون پرانتز) اجرا کنید تا ببینید چه چیزی برگردانده میشود. در اینجا زیرپرسوجو از مثال قبلی آمده است :
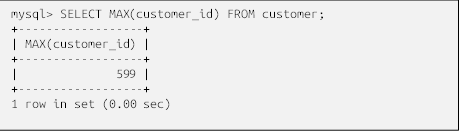
این زیرپرسوجو یک ردیف با یک ستون برمیگرداند که به آن اجازه میدهد به عنوان یکی از بندهای شرطِ برابری از آن استفاده شود (اگر زیرپرسوجو دو یا چند ردیف را برگرداند، میتوان آن را با چیزی مقایسه کرد اما این نتیجه نمیتواند با چیزی برابر باشد. بعداً بیشتر در این مورد صحبت خواهیم کرد). در این حالت، میتوانید مقداری را که زیرپرسوجو برگردانده است، در عبارت سمت راست شرط فیلتر در پرسوجوی حاوی آن جایگزین کنید، مانند زیر:
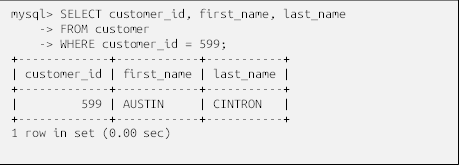
در این مورد، زیرپرسوجو مفید است زیرا به شما امکان میدهد اطلاعات مربوط به مشتری که بالاترین شناسه را دارد در یک پرسوجو بازیابی کنید، نه اینکه حداکثر customer_id را با استفاده از یک پرسوجو بازیابی کنید و سپس یک پرسوجوی دوم برای بازیابی دادههای مورد نظر از جدول مشتری بنویسید. همانطور که خواهید دید، زیرپرسوجوها در بسیاری از موقعیتهای دیگر نیز مفید هستند و ممکن است در جعبه ابزار SQL شما به یکی از قدرتمندترین ابزارها تبدیل شوند.
در کنار تفاوتهایی که قبلاً در مورد نوع مجموعه نتایج برگردانده شده توسط یک زیرپرسوجو (یک سطر/ یک ستون، یک سطر/چند ستون، یا چند سطر/چند ستون) ذکر شد، میتوانید از ویژگی دیگری برای تمایز زیرپرسوجوها استفاده کنید؛ برخی از زیرپرسوجوها کاملاً مستقل هستند (که زیرپرسوجوهای غیر همبسته (Noncorrelated Subqueries) نامیده میشوند)، در حالی که برخی دیگر به ستونهایی از عبارت دربردارنده ارجاع میدهند (که زیرپرسوجوهای همبسته نامیده میشوند). بخشهای بعدی این دو نوع زیرپرسوجو را بررسی میکنند و عملگرهای مختلفی که میتوانید برای تعامل با آنها به کار ببرید، را نشان میدهند.
مثالی که در ابتدای فصل آمده است، یک زیرپرسوجوی غیر همبسته است؛ این زیرپرسوجو میتواند به تنهایی اجرا شود و به هیچ چیزی از عبارتِ دربردارنده آن رجوع نمیکند. اکثر زیرپرسوجوهایی که با آنها مواجه میشوید از این نوع هستند، مگر اینکه در حال نوشتن دستورات بهروزرسانی یا حذف باشید که اغلب از زیرپرسوجوهای همبسته استفاده میکنند (بعداً در این مورد بیشتر صحبت خواهیم کرد). مثالی که در ابتدای فصل آمده بود، علاوه بر غیرهمبسته بودن، یک مجموعه نتیجه شامل یک ردیف و ستون را نیز برمیگرداند. این نوع زیرپرسوجو به عنوان زیرپرسوجوی اسکالر (scalar subquery) شناخته میشود و میتواند همراه با عملگرهای معمول (=، <>، <، >، <=، >=)، در هر دو طرف یک شرط ظاهر شود. مثال بعدی نشان میدهد که چگونه میتوانید از یک زیرپرسوجوی اسکالر در یک شرط نامساوی استفاده کنید:
این پرسوجو تمام شهرهایی که در هند نیستند را برمیگرداند. زیرپرسوجویی که در آخرین خط دستور قرار دارد، شناسه کشور هند را برمیگرداند و زیرپرسوجوی دربردارنده آن، تمام شهرهایی که شناسه آن کشور را ندارند را برمیگرداند. اگرچه زیرپرسوجویی که در این مثال آمده خیلی ساده است، اما زیرپرسوجوها میتوانند به همان اندازه که شما نیاز دارید پیچیده باشند و شما میتوانید از هر یک از بندهای پرسوجو (select، from، where، group by، having و order by) استفاده کنند.
...........................................
محتویات کامل این کتاب در 18 فصل و 550 صفحه منتشر شده، برای ادامه مطالعه این کتاب میتوانید نسخه کامل PDF آن را تهیه کنید.
تا الان، شما باید با مفهوم اتصال درونی (inner join) که در فصل ۵ معرفی کردم، آشنا شده باشید. این فصل بر روشهای دیگر اتصال جداول، از جمله اتصال خارجی (outer join) و اتصال متقاطع (cross join) تمرکز دارد.
در تمام مثالهایی که تاکنون شامل چندین جدول بودهاند، ما نگران این نبودهایم که شرایط اتصال ممکن است در یافتن تطابق برای همه ردیفهای جداول ناموفق باشند. به عنوان مثال، جدول inventory شامل یک ردیف برای هر فیلم موجود برای اجاره است، اما از ۱۰۰۰ ردیف در جدول film، تنها ۹۵۸ مورد یک یا چند ردیف در جدول موجودی دارند. ۴۲ فیلم دیگر برای اجاره در دسترس نیستند (شاید نسخههای جدیدی باشند که قرار است طی چند روز آینده برسند)، بنابراین این شناسههای فیلم را نمیتوان در جدول inventory پیدا کرد. پرسوجوی زیر با اتصال این دو جدول تعداد نسخههای موجود از هر فیلم را میشمارد:
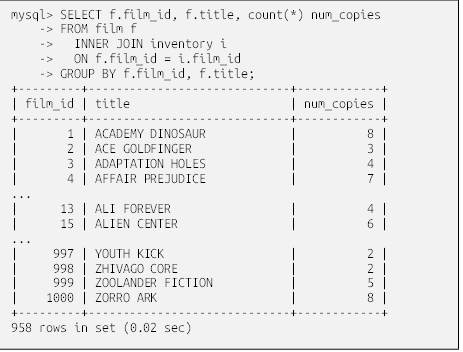
در حالی که ممکن است انتظار داشته باشید ۱۰۰۰ ردیف (یکی برای هر فیلم) برگردانده شود، پرسوجو فقط ۹۵۸ ردیف برمیگرداند. دلیل این امر این است که پرسوجو از یک پیوند درونی استفاده میکند که فقط ردیفهایی را برمیگرداند که شرط پیوند را برآورده میکنند. به عنوان مثال، فیلم Alice Fantasia (film_id 14) در نتایج ظاهر نمیشود، زیرا هیچ ردیفی در جدول inventory ندارد.
اگر صرف نظر از اینکه ردیفهایی در جدول موجودی وجود دارد یا خیر، میخواهید پرسوجو تمام ۱۰۰۰ فیلم را برگرداند، میتوانید از یک پیوند بیرونی استفاده کنید که اساساً شرط پیوند را اختیاری میکند:
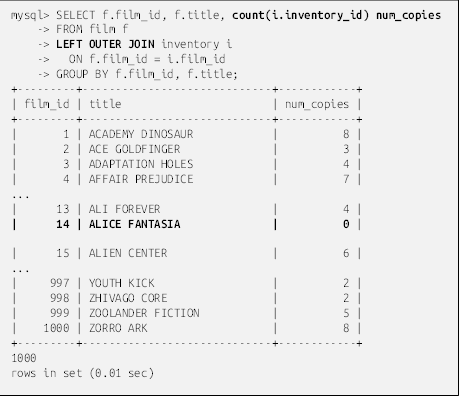
همانطور که میبینید، حالا پرسوجو تمام ۱۰۰۰ ردیفِ جدول film را برمیگرداند و ۴۲ ردیف (از جمله ALICE FANTASIA) در ستون num_copies مقدار ۰ دارند که نشان میدهد هیچ نسخهای در inventory وجود ندارد.
در اینجا شرح تغییرات نسبت به نسخه قبلی پرسوجو آمده است :
· تعریف اتصال ازinner به left outer تغییر یافته است، که به سرور دستور میدهد تمام ردیفهای جدول را در سمت چپ اتصال (در این مورد، film) قرار دهد و سپس در صورت موفقیتآمیز بودن اتصال، ستونهای جدول را در سمت راست اتصال (inventory) قرار دهد.
· تعریف ستون num_copies از count(*) به count(i.inventory_id) تغییر یافت، که تعداد مقادیر غیر تهی ستون inventory.inventory_id را شمارش میکند.
در مرحله بعد اجازه دهید گروه را بر اساس بند حذف کنیم و بیشتر ردیفها را فیلتر کنیم تا تفاوتهای بین پیوندهای داخلی و خارجی به وضوح دیده شود. در اینجا یک پرسوجو با استفاده از یک اتصال inner و یک شرط فیلتر برای بازگرداندن ردیفهای فقط چند فیلم وجود دارد
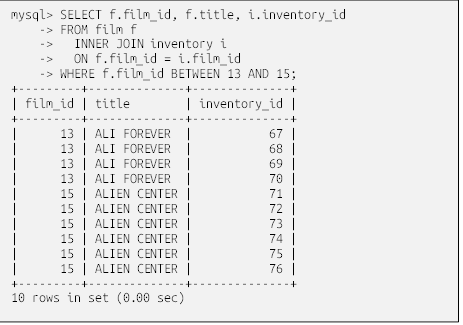
نتایج نشان میدهد که چهار کپی از Ali Forever و شش کپی از Alien Center در فهرست موجودی وجود دارد. در اینجا همان پرسوجو آمده است، اما با استفاده از یک پیوند بیرونی
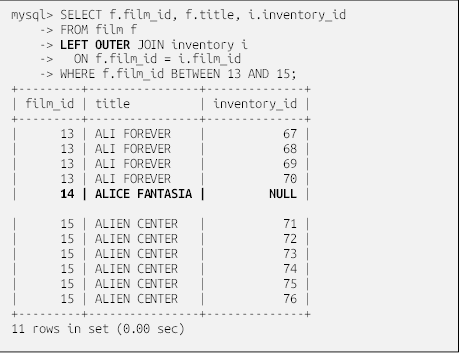
نتایج برای Ali Forever و Alien Center یکسان است، اما یک ردیف جدید برای Alice Fantasia وجود دارد که مقدار آن برای ستون inventory.inventory_id برابر با null است. این مثال نشان میدهد که چگونه یک اتصال بیرونی، مقادیر ستونها را بدون محدود کردن تعداد ردیفهای برگردانده شده توسط پرسوجو، جمع میکند. اگر شرط اتصال با شکست مواجه شود (مانند مورد Alice Fantasia)، هر ستونی که از جدول اتصال بیرونی بازیابی شود، null خواهد بود.
...........................................
محتویات کامل این کتاب در 18 فصل و 550 صفحه منتشر شده، برای ادامه مطالعه این کتاب میتوانید نسخه کامل PDF آن را تهیه کنید.
در شرایط معینی در SQL، بسته به مقادیر ستونها یا عبارات، شما ممکن است بخواهید نحوه کارتان به جهات مختلف منشعب شود. این فصل بر نحوه نوشتن دستوراتی تمرکز دارد که میتوانند بسته به دادههایی که در طول اجرای دستور با آنها مواجه میشوند، رفتار متفاوتی داشته باشند. مکانیسم مورد استفاده برای منطق شرطی در دستورات SQL، عبارت case است که میتواند در دستورات select، insert، update و delete مورد استفاده قرار گیرد.
به طور ساده، منطق شرطی عبارت است از توانایی انتخاب یک مسیر از میان چندین مسیر در طول اجرای برنامه. به عنوان مثال، هنگام پرسوجوی اطلاعات مشتری، ممکن است شما بخواهید ستون customer.active را نیز اضافه کنید که عدد 1 را برای نشان دادن فعال بودن حساب مشتری و عدد 0 را برای نشان دادن غیرفعال بودن آن ذخیره کرده. اگر از نتایج پرسوجو برای تولید یک گزارش استفاده میشود، ممکن است بخواهید این مقادیر به عبارات بهتری ترجمه کنید. در حالی که هر پایگاه داده شامل توابع داخلی برای این نوع موقعیتها است، هیچ استاندارد واحدی وجود ندارد، بنابراین باید به خاطر داشته باشید که کدام توابع توسط کدام پایگاه داده استفاده میشوند. خوشبختانه، پیادهسازی SQL تمام پایگاههای داده شامل عبارت case است که در بسیاری از موقعیتها، از جمله چنین مواردی مفید است:
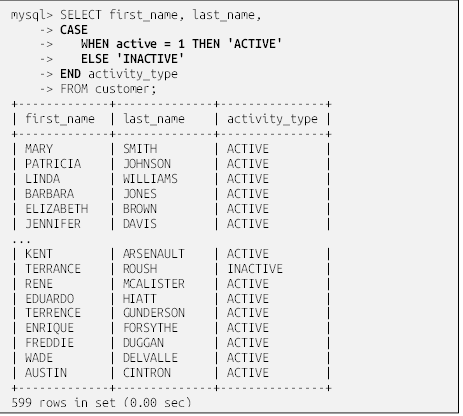
این پرسوجو شامل یک عبارت case برای تولید مقداری برای ستون activity_type است که بسته به مقدار ستون customer.active، رشتهی ACTIVE یا INACTIVE را برمیگرداند.
تمام سرورهای پایگاه داده مهم شامل توابع داخلی هستند که برای تقلید از دستور if-then-else که در اکثر زبانهای برنامهنویسی یافت میشود، طراحی شدهاند (مثلاً تابع decode() در Oracle، تابع if() در MySQL و تابع coalesce() در SQL Server). عبارات case نیز برای تسهیل منطق if-then-else طراحی شدهاند، اما نسبت به توابع داخلی از دو مزیت برخوردار است:
· عبارت case بخشی از استاندارد SQL (نسخه SQL92) است و توسط Oracle Database، SQL Server، MySQL، PostgreSQL، IBM UDB و دیگران پیادهسازی شده است.
· عبارات case در گرامر SQL تعبیه شده و میتواند در دستورات select، insert، update و delete گنجانده شود.
دو بخش بعدی، دو نوع مختلف از عبارات شرطی را معرفی میکنند. در ادامه، چند مثال از عبارات شرطی بطورت عملی آورده شده.
عبارت case که قبلاً در این فصل نشان داده شد، نمونهای از عبارت case جستجو شده است که دارای سینتاکس زیر هستند:
![CASE
WHEN C1 THEN E1
WHEN C2 THEN E2
...
WHEN CN THEN EN
[ELSE ED]
END](sum_files/image069.png)
...........................................
محتویات کامل این کتاب در 18 فصل و 550 صفحه منتشر شده، برای ادامه مطالعه این کتاب میتوانید نسخه کامل PDF آن را تهیه کنید.
تمام مثالهایی که تاکنون در این کتاب آمدهاند، دستوراتِ مستقل و منفرد SQL بودهاند. اگرچه این ممکن است برای گزارشهای موردی یا اسکریپتهای نگهداری دادهها، امری عادی باشد، ولی منطق برنامهها اغلب شامل چندین دستور SQL است که باید به عنوان یک واحد کاری منطقی، همگی با هم اجرا شوند. این فصل به بررسی تراکنشها (transactions) میپردازد که مکانیسمی برای گروهبندی مجموعهای از دستورات SQL با هم هستند، به طوری که یا همه دستورات، یا هیچ یک از آنها، به طور موفق اجراء نمیشوند.
سیستمهای مدیریت پایگاه داده به یک کاربر واحد اجازه میدهند تا دادهها را جستجو کرده و آنها را تغییر دهد، اما در دنیای امروز ممکن است هزاران نفر به طور همزمان در یک پایگاه داده تغییراتی ایجاد کنند. اگر هر کاربر فقط در حال اجرای جستجو باشد، مثلاً پیدا کردن یک قلم در یک انبار، مشکلات بسیار کمی برای سرور پایگاه داده وجود دارد. ولی اگر برخی از کاربران در حال اضافه کردن و/یا تغییر دادهها باشند، سرور باید موارد بسیار بیشتری را ثبت کند.
فرض کنید در حال تهیه گزارشی هستید که خلاصهای از فعالیت اجاره فیلم در هفته جاری را نشان میدهد. همزمان با تهیه این گزارش، فعالیتهای زیر نیز در حال انجام است:
· یک مشتری فیلمی را اجاره میکند.
· یک مشتری فیلمی را پس از تاریخ سررسید آن برمیگرداند و جریمه دیرکرد میپردازد.
· پنج فیلم جدید به فهرست فیلمهای اکران شده اضافه شد.
پس در حالی که گزارش شما در حال اجرا است، چندین کاربر در حال تغییر دادههای اساسی هستند، پس چه اعدادی باید در گزارش شما ظاهر شوند؟ پاسخ تا حدودی به نحوه مدیریت قفلگذاری توسط سرور شما بستگی دارد که در بخش بعدی توضیح داده میشود.
قفلها (Locks) ساز و کاری هستند که سرور پایگاه داده برای کنترل استفاده همزمان از منابع داده آنها را بکار میگیرد. هنگامی که بخشی از پایگاه داده قفل میشود، هر کاربر دیگری که مایل به تغییر (یا احتمالاً خواندن) آن دادهها باشد، باید منتظر بماند تا قفل آزاد شود. اکثر سرورهای پایگاه داده از یکی از دو استراتژی قفلگذاری استفاده میکنند:
· تقاضاهایی که برای تغییر دادهها روی پایگاههای داده چیزی را مینویسند باید از سرور درخواستِ قفلِ نوشتن را دریافت کنند، و تقاضاهایی که میخواهد چیزی را از روی پایگاه داده بخوانند باید برای جستجوی دادهها از سرور قفلِ خواندن را درخواست و آن را دریافت کنند. در حالی که چندین کاربر میتوانند دادهها را همزمان بخوانند، در هر زمان برای هر جدول (یا بخشی از آن) فقط یک قفلِ نوشتن ارائه میشود و درخواستهای خواندن تا زمانی که قفل نوشتن آزاد نشود، مسدود میشوند.
· تقاضاهایی که برای تغییر دادهها روی پایگاههای داده چیزی را مینویسند، باید قفل نوشتن را از سرور درخواست و دریافت کنند، اما تقاضاها برای خواندن دادهها برای جستجوی دادهها به هیچ نوع قفلی نیاز ندارند. در عوض، سرور تضمین میکند که یک خواننده از زمان شروع جستجوی خود تا پایان جستجویش، نمای ثابتی از دادهها را مشاهده کند (حتی اگر سایر کاربران در حال ایجاد تغییرات باشند، دادهها یکسان به نظر میرسند). این رویکرد به عنوان نسخهبندی (versioning) شناخته میشود.
هر دو رویکرد مزایا و معایبی دارند. رویکرد اول در صورت وجود درخواستهای زیاد خواندن و نوشتنِ همزمان، میتواند منجر به زمانِ انتظارِ طولانی شود، و رویکرد دوم در صورت وجود پرسوجوهای طولانی در حین تغییر دادهها، میتواند مشکلساز باشد. از بین سه سرور مورد بحث در این کتاب، Microsoft SQL Server از رویکرد اول، Oracle Database از رویکرد دوم و MySQL از هر دو رویکرد استفاده میکند (بسته به انتخاب موتور ذخیرهسازی شما که کمی بعد در این فصل در مورد آن صحبت خواهیم کرد) .
...........................................
محتویات کامل این کتاب در 18 فصل و 550 صفحه منتشر شده، برای ادامه مطالعه این کتاب میتوانید نسخه کامل PDF آن را تهیه کنید.
از آنجا که تمرکز این کتاب بر تکنیکهای برنامهنویسی SQL است، ۱۲ فصل اول بر عناصری از زبان SQL متمرکز شده است که میتوانید از آنها برای ایجاد دستورات اساسی select، insert، update و delete استفاده کنید. با این حال، سایر ویژگیهای پایگاه داده به طور غیرمستقیم بر برنامهای که مینویسید تأثیر میگذارند. این فصل بر دو مورد از این ویژگیها تمرکز دارد، که عبارتند از ایندکسها (indexes) و قیود (constraints).
وقتی ردیفی را در یک جدول وارد میکنید، سرور پایگاه داده تلاش نمیکند دادهها را در مکان خاصی از جدول قرار دهد. برای مثال، اگر یک ردیف به جدول مشتری اضافه کنید، سرور این ردیف را به ترتیب عددی، مثلاً ستون customer_id، یا به ترتیب حروف الفبا از طریق ستون last_name قرار نمیدهد. در عوض، سرور صرفاً دادهها را در مکانِ موجودِ بعدی در فایل قرار میدهد (سرور لیستی از فضای خالی برای هر جدول را نگهداری میکند). بنابراین، وقتی از جدول customer پرسوجو میکنید، سرور برای پاسخ به پرسوجو شما باید تمام ردیفهای جدول را بررسی کند. برای مثال، فرض کنید پرسوجوی زیر را انجام میدهید:
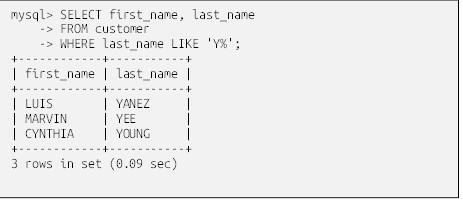
برای یافتن تمام مشتریانی که نام خانوادگی آنها با Y شروع میشود، سرور باید تمام ردیفهای جدول customer را گرفته و محتوای ستون last_name را بررسی کند؛ اگر نام خانوادگی با Y شروع شود، ردیف به مجموعه نتایج اضافه میشود. این نوع دسترسی به عنوان پویش متوالی جدول (table scan) شناخته میشود.
اگرچه این روش برای جدولی که تنها سه ردیف دارد به خوبی کار میکند، ولی تصور کنید که اگر جدول شامل سه میلیون ردیف باشد، پاسخ این پرسوجو چقدر طول میکشد. اگر تعداد ردیفها از حدی بالاتر باشد، اینجا خط قرمزی وجود دارد که در آن سرور نمیتواند بدون استفاده از تکنیک خاصی، در یک مدت زمان معقول به پرسوجو پاسخ دهد. این تکنیک خاص عبارت است از قرار دادن یک یا چند ایندکس (شاخص) در جدول customer.
حتی اگر تا به حال نام ایندکس پایگاه داده (database index) را نشنیده باشید، مطمئناً میدانید که یک ایندکس یا (نمایه یا شاخص) چیست (مثلاً، بعضی از کتابها در صفحات آخر خود دارای یک نمایه یا ایندکس هستند). نمایه صرفاً سازوکاری برای یافتن یک مورد خاص در یک منبع است. به عنوان مثال، هر نشریه فنی شامل نمایهای در انتها آن است که به شما امکان میدهد یک کلمه یا عبارت خاص را در نشریه پیدا کنید. در یک نمایه کلمات و عبارات به ترتیب حروف الفبا فهرست شدهاند و به خواننده اجازه میدهد تا به سرعت به یک حرف خاص در نمایه برود، مدخل مورد نظر را پیدا کند و سپس صفحه یا صفحاتی را که ممکن است کلمه یا عبارت در آن یافت شود، پیدا کند.
همانطور که یک فرد از یک نمایه برای یافتن کلمات در یک نشریه استفاده میکند، یک سرور پایگاه داده نیز از ایندکسها برای یافتن ردیفها در یک جدول استفاده میکند. ایندکسها جداول خاصی هستند که برخلاف جداول داده معمولی، به ترتیب خاصی نگهداری میشوند. با این حال، یک ایندکس به جای اینکه شامل تمام دادههای مربوط به یک موجودیت باشد، همراه با اطلاعاتی که محل فیزیکی ردیفها را توصیف میکند، فقط شامل ستون (یا ستونهایی) است که برای یافتن ردیفها در جدول داده استفاده میشود. بنابراین، نقش ایندکسها تسهیل بازیابی زیرمجموعهای از ردیفها و ستونهای یک جدول بدون نیاز به بررسی هر ردیف در جدول است.
اگر به جدول customer برگردیم، ممکن است شما بخواهید یک ایندکس به ستون ایمیل اضافه کنید تا هرگونه پرسوجویی که مقداری را برای این ستون مشخص میکند، و همچنین هرگونه عملیات بهروزرسانی یا حذف که آدرس ایمیل مشتری را مشخص میکند، سریعتر انجام شود. در اینجا نحوه اضافه کردن چنین ایندکسی به پایگاه داده MySQL آورده شده است:

این دستور روی ستون customer.email یک ایندکس ایجاد میکند (به طور دقیقتر، یک ایندکس B-tree، اما بعداً در این مورد بیشتر توضیح میدهم)؛ علاوه بر این، نام ایندکس idx_email است. با وجود ایندکس، بهینهساز پرسوجو (که در فصل 3 در مورد آن بحث کردیم) میتواند در صورت مفید بودن ایندکس، از آن استفاده کند. اگر بیش از یک ایندکس در یک جدول وجود داشته باشد، بهینهساز باید تصمیم بگیرد که برای یک دستور SQL خاص کدام ایندکس مفیدتر خواهد بود.
...........................................
محتویات کامل این کتاب در 18 فصل و 550 صفحه منتشر شده، برای ادامه مطالعه این کتاب میتوانید نسخه کامل PDF آن را تهیه کنید.
برنامههای کاربردی که خوب طراحیشدهاند معمولاً یک رابط عمومی را در اختیار کاربر قرار میدهند، و در عین حال جزئیات پیادهسازی را خصوصی نگه میدارند، در نتیجه امکان تغییر طراحی در آینده را بدون تأثیر بر کاربران نهایی فراهم میکنند. هنگام طراحی پایگاه داده خود، میتوانید با خصوصی نگه داشتن جداول و اجازه دادن به کاربران خود برای دسترسی به دادهها فقط از طریق مجموعهای از نماها (Views)، به نتیجه مشابهی دست یابید. این فصل تلاش میکند تا تعریف کند که نماها چه هستند، چگونه ایجاد میشوند و چه زمانی و چگونه ممکن است بخواهید از آنها استفاده کنید.
یک نما (view) صرفاً ساز و کاری برای پرسوجوی دادهها است. برخلاف جداول، نماها شامل ذخیرهسازی دادهها نمیشوند، که یعنی نیازی نیست نگران پر شدن فضای دیسک خود توسط نماها باشید. شما با اختصاص دادن یک نام به یک دستور select، و سپس ذخیره پرسوجو برای استفاده دیگران، یک نما را ایجاد میکنید. سپس سایر کاربران میتوانند از نمای شما برای دسترسی به دادهها استفاده کنند، درست مانند اینکه مستقیماً از جداول پرسوجو میکنند (در واقع، ممکن است آنها حتی ندانند که از یک نما استفاده میکنند).
به عنوان یک مثال ساده، فرض کنید میخواهید آدرس ایمیل در جدول مشتریان را تا حدی پنهان کنید. برای مثال، بخش بازاریابی ممکن است برای تبلیغات به آدرسهای ایمیل نیاز داشته باشد، اما در غیر این صورت، سیاست حفظ حریم خصوصی شرکت شما حکم میکند که این دادهها ایمن نگه داشته شوند. بنابراین، به جای اجازه دسترسی مستقیم به جدول مشتریان، یک نما به نام customer_vw تعریف میکنید و همه پرسنل غیربازاریابی را ملزم میکنید که از آن برای دسترسی به دادههای مشتری استفاده کنند. تعریف این نما به شرح زیر است:
بخش اول این دستور، نام ستونهای view را فهرست میکند که ممکن است با نام ستونهای جدول زیرین متفاوت باشد. بخش دوم دستور، یک دستور select است که باید شامل یک عبارت برای هر ستون در view باشد. ستون ایمیل با گرفتن دو حرف اول آدرس ایمیل، الحاق آن با '*****' و سپس الحاق آن با چهار حرف آخر آدرس ایمیل ایجاد میشود.
وقتی دستور create view اجرا میشود، سرور پایگاه داده به سادگی تعریف view را برای استفادههای بعدی ذخیره میکند؛ با اینحال، پرسوجو اجرا نمیشود و هیچ دادهای بازیابی یا ذخیره نمیشود. پس از ایجاد view، کاربران میتوانند درست مانند یک جدول، از آن پرسوجو کنند، مانند:
اگرچه تعریف view مربوط به customer_vw شامل چهار ستون از جدول customer است، اما query قبلی فقط سه ستون از چهار ستون را بازیابی میکند. همانطور که بعداً در این فصل خواهید دید، اگر برخی از ستونهای view به توابع یا زیرپرسوجوها متصل باشند، این یک تمایز مهم است.
از دیدگاه کاربر ، یک نما دقیقاً شبیه یک جدول است. اگر میخواهید بدانید چه ستونهایی در یک نما موجود است، برای بررسی آن میتوانید از دستور describe در MySQL (یا Oracle ) استفاده کنید:
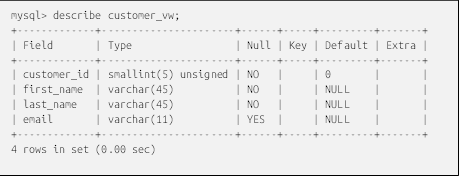
هنگام پرسوجو از طریق یک نما، شما میتوانید از تمام بندهای دستور select، از جمله group by، having و order by، استفاده کنید. در اینجا مثالی آورده شده است :
علاوه بر این، میتوانید نماها را در یک پرسوجو به جداول دیگر (یا حتی به نماهای دیگر) متصل کنید، مانند:
این پرسوجو، نمای customer_vw را به جدول پرداختها متصل میکند تا مشتریانی را پیدا کند که ۱۱ دلار یا بیشتر برای اجاره فیلم پرداخت کردهاند.
در بخش قبلی، یک view ساده را نشان دادم که تنها هدف آن پنهان کردن محتوای ستون customer.email بود. اگرچه اغلب از نماها برای این منظور استفاده میشوند، اما دلایل زیادی برای استفاده از نماها وجود دارد که در بخشهای بعدی به تفصیل توضیح داده شده است.
...........................................
محتویات کامل این کتاب در 18 فصل و 550 صفحه منتشر شده، برای ادامه مطالعه این کتاب میتوانید نسخه کامل PDF آن را تهیه کنید.
سرورهای پایگاه داده علاوه بر ذخیره تمام دادههایی که کاربران مختلف در پایگاه داده وارد میکنند، باید اطلاعات مربوط به تمام اشیاء پایگاه داده (جداول، نماها، ایندکسها و غیره) که برای ذخیره این دادهها ایجاد شدهاند را نیز ذخیره کند. همانطور که انتظار میرود، سرور این اطلاعات را نیز در یک پایگاه داده ذخیره میکند. این فصل به چگونگی و محل ذخیره این اطلاعات، که به عنوان فراداده (Metadata) شناخته میشوند، نحوه دسترسی به آنها، و نحوه استفاده از آنها برای ساخت سیستمهای انعطافپذیر میپردازد.
اساساً فرادادهها عبارتند از دادههایی که درباره دادهها هستند. هر بار که یک شیء پایگاه داده ایجاد میکنید، سرور پایگاه داده باید اطلاعات مختلفی را ثبت کند. برای مثال، اگر قرار باشد جدولی با چندین ستون، یک قید کلید اصلی، سه ایندکس و یک قید کلید خارجی ایجاد کنید، سرور پایگاه داده باید تمام اطلاعات زیر را ذخیره کند:
· نام جدول
· اطلاعات ذخیرهسازی جدول (فضای جدول، اندازه اولیه آن و غیره)
· موتور ذخیرهسازی
· نام ستونها
· گونه ستونها
· مقادیر پیشفرض ستونها
· قیود ستونهای غیر تهی
· ستونهای کلید اصلی
· نام کلید اصلی
· نام ایندکس کلید اصلی
· نام ایندکسها
· گونه ایندکسها (درخت B، بیتمپ)
· ستونهای ایندکس شده
· ترتیب مرتبسازی ستونهای ایندکس (صعودی یا نزولی)
· اطلاعات ذخیرهسازی ایندکسها
· نام کلید خارجی
· ستونهای کلید خارجی
· جدول/ستونهای مرتبط با کلیدهای خارجی
در مجموع این دادهها به عنوان فرهنگ لغت دادهها (data dictionary )، یا کاتالوگ سیستم شناخته میشوند. سرور پایگاه داده باید این دادهها را به طور مداوم ذخیره کند و باید بتواند به سرعت این دادهها را بازیابی کند تا بتواند دستورات SQL را تأیید و اجرا کند. علاوه بر این، سرور پایگاه داده باید از این دادهها محافظت کند تا آنها از طریق یک مکانیسم مناسب، مانند دستور alter table، قابل تغییر باشند.
اگرچه استانداردهایی برای تبادل فراداده بین سرورهای مختلف وجود دارد، اما هر سرور پایگاه داده از مکانیسم متفاوتی برای انتشار فراداده استفاده میکند، مانند:
· مجموعهای از نماها، مانند نماهای user_tables و all_constraints در پایگاه داده Oracle
· مجموعهای از رویههای ذخیرهشده در سیستم، مانند رویه sp_tables در SQL Server یا بسته dbms_metadata در Oracle Database
· یک پایگاه داده خاص، مانند information_schema در MySQL
SQL Server علاوه بر رویههای ذخیرهشده سیستمی خودش، که بازماندهای از نسل Sybase هستند، شامل یک طرحواره ویژه به نام information_schema نیز میشود که به طور خودکار در هر پایگاه داده ارائه میشود. هم MySQL و هم SQL Server این رابط را برای مطابقت با استاندارد ANSI SQL:2003 ارائه میدهند. ادامه این فصل به بررسی اشیاء information_schema موجود در MySQL و SQL Server میپردازد.
تمام اشیاء موجود در پایگاه داده information_schema (یا schema، در مورد SQL Server)، نوعی نما هستند. برخلاف دستور describe که قبلاً به عنوان راهی برای نشان دادن ساختار جداول و نماهای مختلف استفاده کردم، میتوان از نماهای درون information_schema پرسوجو کرد، و از این جهت، در برنامهنویسی از آنها استفاده کرد (در ادامه فصل بیشتر در این مورد صحبت خواهیم کرد). در زیر مثالی آمده که نحوه بازیابی نام تمام جداول در پایگاه داده Sakila را نشان میدهد:
همانطور که میبینید، نمای information_schema.tables شامل جداول و نماها میشود؛ اگر میخواهید نماها را حذف کنید، کافیست یک شرط دیگر به عبارت where اضافه کنید:
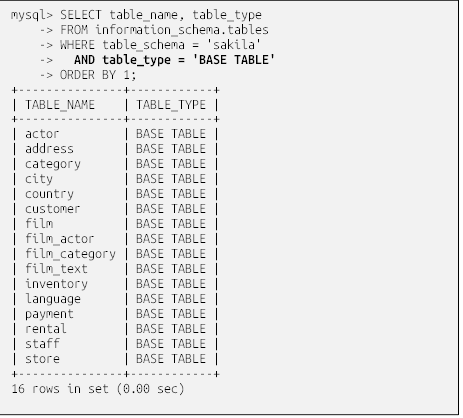
...........................................
محتویات کامل این کتاب در 18 فصل و 550 صفحه منتشر شده، برای ادامه مطالعه این کتاب میتوانید نسخه کامل PDF آن را تهیه کنید.
حجم دادهها با سرعت سرسامآوری در حال افزایش است و سازمانها در ذخیره همه آنها مشکل دارند، چه برسد تلاش کنند آنها را درک کنند. در حالی که تجزیه و تحلیل دادهها به طور سنتی خارج از سرور پایگاه داده و با استفاده از ابزارها یا زبانهای تخصصی مانند Excel، R و Python انجام میشود، زبان SQL شامل مجموعهای قوی از توابع مفید برای پردازشهای تحلیلی است. اگر نیاز به ایجاد رتبهبندی برای شناسایی 10 فروشنده برتر در شرکت خود دارید، یا اگر در حال تهیه گزارش مالی برای مشتری خود هستید و نیاز به محاسبه میانگینهای سه ماهه دارید، برای انجام این نوع محاسبات میتوانید از توابع تحلیلی داخلی SQL استفاده کنید .
پس از اینکه سرور پایگاه داده تمام مراحل لازم برای ارزیابی یک پرسوجو، از جمله اتصال، فیلتر کردن، گروهبندی، و مرتبسازی را انجام داد، مجموعه نتایج کامل شده و آماده بازگشت است. تصور کنید اگر میتوانستید اجرای پرسوجو را در این مرحله متوقف کنید، و در حالی که مجموعه نتایج هنوز در حافظه نگهداری میشود، نگاهی به آنها بیندازید؛ چه نوع تحلیلی ممکن است بخواهید انجام دهید؟ اگر مجموعه نتایج شما حاوی دادههای فروش باشد، شاید بخواهید رتبهبندیهایی برای فروشندگان یا مناطق فروش ایجاد کنید، یا درصد تفاوتها را بین یک دوره زمانی و دوره زمانی دیگر محاسبه کنید. اگر در حال تولید نتایج برای یک گزارش مالی هستید، شاید بخواهید برای تمام بخشهای گزارش، جمعهای جزئی، و برای بخش نهایی جمع کلی را محاسبه کنید. با استفاده از توابع تحلیلی، میتوانید همه این کارها و موارد دیگری را انجام دهید. قبل از پرداختن به جزئیات، زیربخشهای مکانیسم مورد استفاده توسط چندین مورد از رایجترین توابع تحلیلی را شرح میدهند.
فرض کنید شما یک پرسوجو نوشتهاید که مجموع فروش ماهانه را برای یک دوره زمانی مشخص تولید میکند. برای مثال، پرسوجوی زیر مجموع پرداختهای ماهانه برای اجاره فیلم را برای دوره مه تا آگوست ۲۰۰۵ جمع میکند:
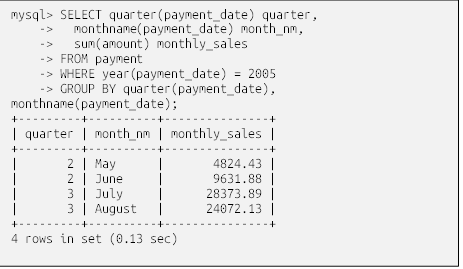
با نگاهی به نتایج، میتوانید ببینید که ماه جولای بالاترین مجموع ماهانه را در هر چهار ماه و ماه ژوئن بالاترین مجموع ماهانه را برای سه ماهه دوم داشته است. با این حال، برای تعیین بالاترین مقادیر به صورت برنامهنویسی، باید ستونهای اضافی را به هر ردیف اضافه کنید که حداکثر مقادیر را در هر سه ماهه و در کل دوره زمانی نشان میدهد. در اینجا - پرسوجوی قبلی با دو ستون جدید برای محاسبه این مقادیر آمده است:
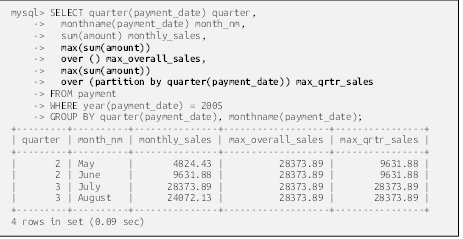
توابع تحلیلی مورد استفاده برای تولید این ستونهای اضافی، ردیفها را در دو مجموعه مختلف گروهبندی میکنند: یک مجموعه شامل تمام ردیفها در یک مدت سه ماهه، و مجموعه دیگر شامل تمام ردیفها. برای تطبیق با این نوع تحلیل، توابع تحلیلی شامل قابلیت گروهبندی ردیفها در پنجرهها هستند که به طور مؤثر دادهها را برای استفاده توسط تابع تحلیلی بدون تغییر مجموعه نتایج کلی، تقسیمبندی میکنند. پنجرهها با استفاده از بندِ over همراه با یک زیربندِ اختیاری partition by تعریف میشوند. در پرسوجوی قبلی، هر دو تابع تحلیلی شامل یک بندِ over هستند، اما اولی خالی است، که نشان میدهد پنجره باید شامل کل مجموعه نتایج باشد، در حالی که دومی مشخص میکند که پنجره فقط باید شامل ردیفهای داخل یک مدت سه ماهه باشد. پنجرههای داده ممکن است از یک ردیف واحد تا تمام ردیفهای مجموعه نتایج را شامل شوند و توابع تحلیلی مختلف میتوانند پنجرههای داده متفاوتی را تعریف کنند.
همراه با تقسیمبندی مجموعه نتایج خود به پنجرههای داده برای توابع تحلیلی، میتوانید یک ترتیب مرتبسازی نیز مشخص کنید. برای مثال، اگر میخواهید برای هر ماه یک شماره رتبهبندی تعریف کنید، که در آن مقدار ۱ به ماهی که بیشترین فروش را دارد داده میشود، باید مشخص کنید که از کدام ستون (یا ستونها) برای رتبهبندی استفاده کنید:
...........................................
محتویات کامل این کتاب در 18 فصل و 550 صفحه منتشر شده، برای ادامه مطالعه این کتاب میتوانید نسخه کامل PDF آن را تهیه کنید.
در روزهای اولیه پایگاههای داده رابطهای، ظرفیت هارد دیسک بر حسب مگابایت اندازهگیری میشد و کلاً مدیریت پایگاههای داده آسان بود، زیرا حجم آنها خیلی بزرگ نبود. ولی امروزه ظرفیت یک هارد دیسک به 15 ترابایت افزایش یافته است، و آرایهای از دیسکهای جدید میتواند بیش از 4 پتابایت داده را ذخیره کند، و ذخیرهسازی ابری اساساً نامحدود است. در حالی که پایگاههای داده رابطهای با چالشهای مختلفی روبرو هستند، زیرا حجم دادهها همچنان در حال افزایش است، استراتژیهایی مانند پارتیشنبندی، خوشهبندی، و خُرد کردن وجود دارد که به شرکتها اجازه میدهد با پخش دادهها در چندین ردیف ذخیرهسازی، سرورها به استفاده از پایگاههای داده رابطهای ادامه دهند. سایر شرکتها تصمیم گرفتهاند برای مدیریت حجم عظیمِ دادهها به پلتفرمهای دادههای کلان، مانند Hadoop روی آورند. این فصل به برخی از این استراتژیها، با تأکید بر تکنیکهای مقیاسبندی پایگاههای داده رابطهای، میپردازد.
حقیقتاً چه موقع یک جدول پایگاه داده «خیلی بزرگ» میشود؟ اگر این سوال را از 10 متخصص پایگاه داده مختلف بپرسید، احتمالاً 10 پاسخ متفاوت دریافت خواهید کرد. با این حال، اکثر مردم موافقند که با رسیدن تعداد ردیفهای یک جدول به چند میلیون، وظایف زیر دشوارتر یا زمانبرتر میشوند:
· اجرای یک پرسوجو که به پویش کامل جدول نیاز دارد
· ایجاد و بازسازی ایندکسها
· بایگانی و حذف دادهها
· تولید آمار جدول/ایندکس
· جابجایی جدول (مثلاً انتقال به یک جدول متفاوت)
· پشتیبانگیری از پایگاه داده
زمانی که یک پایگاه داده کوچک است، این کارها میتوانند به صورت عادی شروع شوند، سپس با تجمع دادههای بیشتر، زمانبر شوند، و سپس به دلیل محدودیتهای زمانی مدیریتی، مشکلساز یا حتی غیرممکن شوند. هنگام ایجاد جداول بزرگ، بهترین راه برای جلوگیری از وقوع مشکلات مدیریتی در آینده، شکستن آنها به قطعاتی که پارتیشن (partition) نامیده میشوند، است (اگرچه جداول را میتوان بعداً پارتیشنبندی کرد، اما انجام این کار در ابتدا آسانتر است). کارهای مدیریتی را میتوان روی پارتیشنهای جداگانه، اغلب به صورت موازی، انجام داد و برخی از کارها میتوانند یک یا چند پارتیشن را به طور کامل نادیده بگیرند.
پارتیشنبندی جداول در اواخر دهه ۱۹۹۰ توسط اوراکل معرفی شد، اما از آن زمان به بعد، تمام سرورهای عمده پایگاه داده، قابلیت پارتیشنبندی جداول و ایندکسها را دارند. هنگامی که یک جدول پارتیشنبندی میشود، دو یا چند پارتیشن جدول ایجاد میشوند که هر کدام تعریف دقیقاً یکسان دارند اما زیرمجموعههای دادههای آنها با هم تداخل ندارند. به عنوان مثال، یک جدول حاوی دادههای فروش میتواند با استفاده از ستونی که حاوی تاریخ فروش است، بر اساس ماه پارتیشنبندی شود، یا میتواند با استفاده از کد ایالت/استان بر اساس منطقه جغرافیایی پارتیشنبندی شود.
پس از پارتیشنبندی یک جدول، خودِ جدول به یک مفهوم مجازی تبدیل میشود؛ پارتیشنها دادهها را در خود نگه میدارند و هر ایندکسی بر اساس دادههای موجود در پارتیشنها ساخته میشود. با این حال، کاربران پایگاه داده همچنان میتوانند بدون اطلاع از پارتیشنبندی جدول، با جدول تعامل داشته باشند. این مفهوم مشابه یک نما است، به این صورت که کاربران با اشیاء طرحواره که رابط هستند، نه جداول واقعی، تعامل دارند. در حالی که هر پارتیشن باید تعریف طرحواره یکسانی (ستونها، گونه ستون، و غیره) داشته باشد، چندین ویژگی مدیریتی وجود دارد که میتواند برای هر پارتیشن متفاوت باشد:
· پارتیشنها میتوانند در tablespaceهای مختلف ذخیره شوند که میتوانند در سطوح ذخیرهسازی فیزیکی متفاوتی باشند.
· پارتیشنها را میتوان با استفاده از طرحهای فشردهسازی مختلف فشرده کرد.
· برای برخی از پارتیشنها، میتوان ایندکسهای محلی (به زودی در این مورد بیشتر توضیح خواهیم داد) را حذف کرد.
· آمار جدول میتواند در برخی از پارتیشنها ثابت بماند، در حالی که در پارتیشنهای دیگر به صورت دورهای بهروزرسانی میشود.
· پارتیشنهای جداگانه را میتوان در حافظه چسباند (pin) یا در لایه ذخیرهسازی فلشِ پایگاه داده ذخیره کرد .
بنابراین، پارتیشنبندی جدول امکانِ انعطافپذیری در ذخیرهسازی و مدیریت دادهها را فراهم میکند، در حالی که همچنان سادگی یک جدولِ واحد را برای کاربران شما ارائه میدهد.
طرح پارتیشنبندی موجود در اکثر پایگاههای داده رابطهای، پارتیشنبندی افقی (horizontal partitioning) است که در آن کلِ ردیفها دقیقاً به یک پارتیشن اختصاص میدهد. همچنین جداول میتوانند به صورت عمودی پارتیشنبندی (vertically) شوند که شامل اختصاص مجموعهای از ستونها به پارتیشنهای مختلف است، اما این کار باید به صورت دستی انجام شود. هنگام پارتیشنبندی افقی یک جدول، باید یک کلید پارتیشن انتخاب کنید، که عبارت است از ستونی که مقادیر آن برای اختصاص یک ردیف به یک پارتیشن خاص استفاده میشود. در بیشتر موارد، کلیدِ پارتیشنِ یک جدول از یک ستون تشکیل شده است و یک تابع پارتیشنبندی روی این ستون اعمال میشود تا مشخص شود هر ردیف باید در کدام پارتیشن قرار گیرد.
اگر جدولِ پارتیشنبندی شده شما دارای ایندکس باشد، میتوانید انتخاب کنید که آیا یک ایندکس خاص دستنخورده باقی بماند، که به عنوان ایندکس سراسری (global index) شناخته میشود، یا به قطعاتی تقسیم شود که هر پارتیشن ایندکس مخصوص به خود را داشته باشد، که به آن ایندکس محلی گفته میشود. ایندکسهای سراسری تمام پارتیشنهای جدول را در بر میگیرند و برای پرسوجوهایی که مقداری برای کلید پارتیشن مشخص نمیکنند، مفید هستند. به عنوان مثال، فرض کنید جدول شما بر اساس ستون sale_date پارتیشنبندی شده است و کاربر پرسوجوی زیر را اجرا میکند:
![]()
...........................................
محتویات کامل این کتاب در 18 فصل و 550 صفحه منتشر شده، برای ادامه مطالعه این کتاب میتوانید نسخه کامل PDF آن را تهیه کنید.
اگرچه بیشتر محتوای این کتاب به ویژگیهای مختلف زبان SQL هنگام استفاده از یک پایگاه داده رابطهای مانند MySQL میپردازد، اما چشمانداز دادهها در طول دهه گذشته تغییرات زیادی کرده است و SQL نیز برای پاسخگویی به نیازهای محیطهای به سرعت در حال تحول امروزی، در حال تغییر است . بسیاری از سازمانهایی که تنها چند سال پیش منحصراً از پایگاههای داده رابطهای استفاده میکردند، حالا دادهها را در خوشههای Hadoop، دریاچههای داده و پایگاههای داده NoSQL نیز نگهداری میکنند. در عین حال، شرکتها در تلاشند تا راههایی برای کسب بینش از حجم رو به رشد دادهها پیدا کنند و این واقعیت که این دادهها اکنون در چندین مخزن داده، هم بصورت محلی و هم ابری، پخش شدهاند، این کار را به یک کار دلهرهآور تبدیل میکند.
از آنجا که SQL توسط میلیونها نفر استفاده میشود و در هزاران برنامه کاربردی ادغام شده است، منطقی است که از SQL برای مهار این دادهها و کاربردی کردن آنها استفاده شود. در طول چند سال گذشته، نسل جدیدی از ابزارها برای فعال کردن دسترسی SQL به دادههای ساختاریافته، نیمه ساختاریافته و بدون ساختار پدیدار شدهاند: ابزارهایی مانند Presto، Apache Drill و Toad Data Point. این فصل به بررسی یکی از این ابزارها، Apache Drill، میپردازد تا نشان دهد که چگونه میتوان دادهها را در قالبهای مختلف و ذخیره شده در سرورهای مختلف برای گزارشدهی و تجزیه و تحلیل گرد هم آورد.
ابزارها و رابطهای متعددی برای دسترسی SQL به دادههای ذخیره شده در Hadoop، NoSQL، Spark و سیستمهای فایل توزیع شده مبتنی بر اَبر توسعه داده شدهاند. مثلاً میتوان به Hive اشاره کرد که یکی از اولین تلاشها برای فراهم کردن امکان پرسوجوی کاربران از دادههای ذخیره شده در Hadoop بود و Spark SQL که کتابخانهای است که برای پرسوجوی دادههای ذخیره شده در فرمتهای مختلف از داخل Spark استفاده میشود. یکی از تازهواردان، Apache Drill است که متنباز میباشد و اولین بار در سال ۲۰۱۵ به بازار آمد و ویژگیهای جذاب زیر را دارد:
· پرسوجوها را در قالبهای دادهای مختلف، از جمله دادههای محدود، JSON، Parquet و فایلهای لاگ، تسهیل میکند.
· به پایگاههای داده رابطهای، Hadoop، NoSQL، HBase و Kafka و همچنین فرمتهای داده تخصصی مانند PCAP، BlockChain و موارد دیگر متصل میشود.
· امکان ایجاد افزونههای سفارشی برای اتصال به اکثر فروشگاههای داده دیگر را فراهم میکند.
· نیازی به تعاریف اولیه طرحواره ندارد
· پشتیبانی از استاندارد SQL:2003
· با ابزارهای محبوب هوش تجاری (BI) مانند Tableau و Apache Superset کار میکند.
شما با استفاده از Drill میتوانید به هر تعداد منبع داده متصل شوید و بدون نیاز به راهاندازی اولیه یک مخزن فراداده، پرسوجو را شروع کنید. بحث در مورد گزینههای نصب و پیکربندی Apache Drill فراتر از محدوده این کتاب است،
بیایید با استفاده از Drill برای جستجوی دادهها در یک فایل شروع کنیم. Drill میداند که چگونه چندین فرمت فایل مختلف، از جمله فایلهای ضبط بسته (PCAP) را بخواند، که به صورت دودویی هستند و حاوی اطلاعاتی در مورد بستههای در حال حرکت در شبکه هستند. تنها کاری که باید انجام دهم وقتی میخواهم یک فایل PCAP را جستجو کنم این است که افزونه dfs (سیستم فایل توزیع شده) Drill را پیکربندی کنم تا مسیر دایرکتوری حاوی فایلهای من را شامل شود، و من آماده نوشتن جستجوها هستم.
اولین کاری که میخواهم انجام دهم این است که بفهمم چه ستونهایی در فایلی که میخواهم پرسوجو کنم، موجود است. دریل شامل پشتیبانی جزئی از information_schema (که در فصل ۱۵ به آن پرداخته شده است) است، بنابراین میتوانید اطلاعات سطح بالایی در مورد فایلهای داده در فضای کاری خود پیدا کنید:
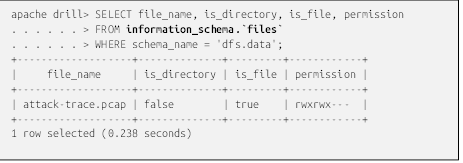
نتایج نشان میدهد که من یک فایل واحد به نام attack-trace.pcap در فضای کاری داده خود دارم که اطلاعات مفیدی است، اما نمیتوانم با استفاده از `information_schema.columns` ستونهای موجود در فایل را پیدا کنم. ولی اجرای یک پرسوجو که هیچ ردیفی در برابر فایل برنمیگرداند، مجموعه ستونهای موجود را نشان میدهد:
حالا که نام ستونهای فایل PCAP را میدانم، آماده نوشتن پرسوجوها هستم. در اینجا یک پرسوجو وجود دارد که تعداد بستههای ارسالی از هر آدرس IP به هر پورت مقصد را میشمارد:
...........................................
محتویات کامل این کتاب در 18 فصل و 550 صفحه منتشر شده، برای ادامه مطالعه این کتاب میتوانید نسخه کامل PDF آن را تهیه کنید.